自动机理论之非确定性有限自动机
从正则表达式到有限自动机
正则语言是由有限状态机(FSM)的形式化来认识的,也被称为有限自动机(FA)。特别是对于正则表达式 —— 由非确定性有限自动机(NFA)和确定性有限自动机(DFA)。
注:从 FSM 的一般理论来看,FAs 分为两类。“有输出的 FA”(Moore machine 和 Mealy machine)和 “无输出的 FA”:NFA、ε-NFA 和 DFA。我们将讨论后一类用于正则表达式实现的 FAs。
除非需要支持扩展的正则表达式功能,如嵌套等,否则 FAs 提供了正则表达式识别器的最快 O(n) 实现,这也是为什么 DFAs 在实践中仍然被广泛使用的原因,例如在自动生成的词法分析器中,如 Lex。
NFA 定义
非确定性有限自动机(NFA) 是一个 5 元组。
1 | NFA = (Q, Σ, δ, q0, F) |
让我们来看看一个简单的 NFA,它将帮助我们理解定义中每个组件的含义。
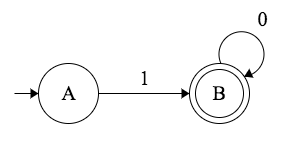
注意:该 NFA 接受
1、10、100、1000等字符串,对应/10*/正则表达式。
定义中的 Q 分量是该机器可能处于的所有状态的集合。在每个时刻,一台机器只能处于其中的一种状态。
在我们的例子中,Q 的集合是:
1 | Q = {A, B} |
其中一个状态,特别是状态 B ,是两个圆圈的。用这个符号我们表示接受状态(或最终状态)。这就是定义中的 F 分量。
1 | F = {B} |
我们遍历这个图的目标,是要达到一个接受状态(至少是接受状态集合中的一个)。但是,我们从哪里开始呢?从状态 q0 开始,这被称为起始状态(或初始状态)。在 FA 图上,起始状态是有一个 “不知从哪里来” 的传入箭头的状态。在我们的例子中,它是状态 A 。
1 | q0 = A |
从状态到状态的转换由 δ 转换函数管理,对于一个 NFA 来说,它被定义为:
1 | δ : Q × Σ → 2^Q |
这个定义简单的说就是 “如果我们处于集合 Q 中的一个状态,并且消耗了字母表 ∑ 中的一个符号,我们就会转换到另一个同样来自集合 Q 中的状态”。
由于 NFA 是不确定的,在同一个符号上的每个状态,我们可以去往来自集合 Q 的所有可能的状态,这就是为什么转换映射到 2^Q 。注意,对于 DFA 来说,这将仅仅映射到 Q 。
转换的例子:
1 | A × 1 → B |
∑ 定义了一个语法(在本例中是机器的)的字母表。我们可以看到标注 transition edges 的字母符号,在我们的例子中,它们是:
1 | Σ = {0, 1} |
基本上就是这样。这些都是允许我们描述任何 NFA 的组成部分。
Nondeterminism
我们来看看下面的 NFA。
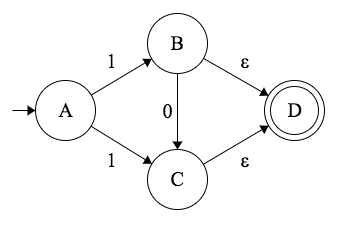
注意:这个 NFA 只接受两个字符串。
1和10,对应于/10?/正则表达式。
NFA 的第一个非确定性方面来自于从同一符号上的当前状态向不同状态转换的能力。看看从状态 A 的转换:
1 | A × 1 → B |
如果我们在这种情况下收到符号 1 ,我们怎么决定去哪里呢?这是个好问题!虽然在技术上是可能的 —— 我们只需要逐一或并行地尝试所有路径,但通常情况下不是这样的,这也是为什么不直接使用 NFAs,而是进一步转换为适当的 DFAs 的原因。
非确定性的第二个方面是,NFA 不需要实现字母表的所有转换:例如,从状态 A 开始,我们只有 A×1 的转换,而没有 A×0 的转换,在一个完全指定的 DFA 中,我们将不得不提供这样的 A×0 转换,这将进入一个 “死亡状态”。然而,即使在 DFA 中,为了简洁起见,我们也可以省略这样的转换。
ε-NFA
另一个只有在 NFA 中才可能出现的属性,就是可以有 epsilon-transitions(又称 ε-transitions)。
注:Epsilon(ε) —— 空字符串。
在上面的例子中,我们可以看到这样的状态 B 和 C 的转换,这意味着,我们可以在不消耗字符串中的一个字符的情况下,从这些状态转换到最后的状态 D。
然而,请注意,ε-transitions 并不能扩展你的 NFA 的功能。它们通常是为了方便组合 NFA 片段的不同部分。
有时,将正则表达式翻译成纯 NFA 比较困难,而翻译成 ε-NFA 则容易得多,这就是为什么通常我们使用后者,并最终将 ε-NFA 转换为 DFA。
而 DFA 只是定义了这些限制 —— 不允许 ε-transitions ,不允许不确定的移动等等。除此以外,它与 NFA 没有太大区别 —— 除了转换函数。
现在让我们看看如何将 NFA 应用于正则表达式吧。
事实上,当我们有一个正则表达式,如 /xy*|z/ ,还不清楚如何将其转化为合适的机器。而通常我们不会这样做。相反,我们将一个复杂的表达式分解成基本的构件(basic building blocks),然后将这些基本构件连接起来,形成结果机。
正则表达式的 5 个基本 NFA 片段
在正则语言的形式定义中,只有 5 种情况,这 5 种情况实际上定义了一种正则语言。而这正是我们在涵盖 basic building NFA-block(我们也称其为 NFA-fragments)时需要的内容。
Character fragment
最简单的 NFA 机器是针对单个字符的机器,比如说 a,对应的正则表达式是 /a/。
其 NFA 片段如下:
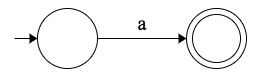
注意:我们在这里特别省略了状态标签,因为在本例中这不是重点。重点在于用字符
a标注的 edge transition。
这个 NFA-fragments 说明:“如果我们处于初始状态,只有从字符串中消耗字符 a,才能转入下一个(最终)状态”。
该片段只接受一个字符串,即字符串 "a":通过消耗字符 a,我们将光标移动到字符串的末端,并过渡到下一个(最终)状态。由于我们处于最终状态,所以我们接受了这个字符串。
在我们的 NFA-fragments 中,我们要像上面的例子一样保持 “一个输入,一个输出” 的不变性。这将使机器与更复杂的复合 NFA 连接起来更加容易。
我们继续看看类似的,但不消耗字符的转换。
ε-transition fragment
正如我们上面提到的,ε-moves 允许我们转换到下一个状态,并将字符串光标保持在原地,也就是不消耗一个字符。
ε-transition 片段看起来和字符转换一样,但不是消耗一个实际的字符,而是在 “空字符” 上转换。
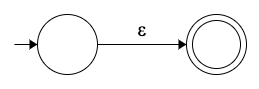
上面讨论的字符和 epsilon 是最基本的 NFA-fragments 。在这两个之上,其他的一切都建立在 FA 正则表达式实现中。
基本集合的最后三个片段称为 basic regexp operations,我们来详细考虑一下它们。
Concatenation fragment
连词 NFA-fragment 定义了 “A 之后是 B” 的操作。它被表示为一个序列 AB,在最简单的例子中可以用 /ab/ 正则表达式来表示。
我们如何呈现这个操作呢?好了,我们知道如何为 A(最简单情况下的单个字符)建造机器,也知道如何为 B(同样最简单情况下的单个字符)建造机器。
我们需要做的只是将机器 A 的输出连接到机器 B 的输入 —— 在 ε-transition 上:

我们可以看到,实际的机器 A 和 B 是被封装的。我们只是在 ε-transitions 时将它们连在一起,而不对这些机器内部的内容做出任何承诺。
也就是说,这些机器都是黑盒抽象:它们可能是单个字符机器 —— 比如 /ab/,甚至可能是一些复杂的复合机器,比如一个重复的字符类后面跟着另一个字符类:/[0-9]*[a-z]/ —— 在这两种情况下,它们仍然遵循于同一个连接片段。
同时注意,一旦我们把机器连起来,我们就会重置第一台机器的接受状态,即我们仍然保持 “一输入一输出” 的不变性。这样就可以把这个合并后的机器当作单一的单元,并把它进一步连接起来。
Union fragment
联合 NFA 片段定义了 “OR” 操作。它也被称为 “disjunction” 操作。
分离式表示为 A|B 操作,最简单的正则表达式可以是这样的:/a|b/。
同样,我们要保持黑盒机器的不变性,保持 “一输入一输出” 的方式:
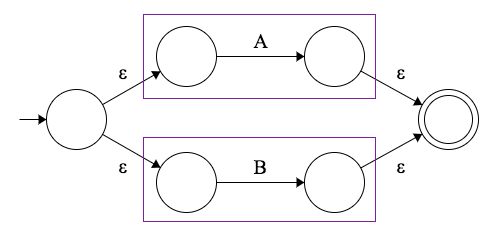
以字符串 "a" 和正则表达式 /a|b/ 为例,让我们看看如何接受它。
从初始状态的非确定性 ε-transition 允许我们从两条路径中选择任何一条。比方说,我们选择了较低的路径,并转换到期望我们消耗 b 字符的状态。但事实并非如此,因为我们正试图匹配 "a",我们现在必须回溯到分割点,并尝试另一条路径。
这个机器很有意思。首先,它表明可以直接解释一个 NFA(通过遍历这个图)。第二,它表明实际上可能会很慢 —— 比如在这个案例中的回溯。当然,我们可以做一些优化,例如,生成几个并行线程,放弃那些碰到死胡同的路径。然而,实践中通常不会出现这种情况,就像我们之前说的那样,我们最终要把这个 NFA 转换为合适的 DFA,这样会快很多。
最后一个我们要考虑的是 Kleene-closure。
Kleene-closure fragment
Kleene-closure(又叫 Kleene-star)操作定义了重复模式,用更方便的方式说就是重复一台机器的 “零次或多次”。
Kleene-star 表示为 A*,在最简单的正则表达式中看起来是 /a*/ 。它接受的字符串有 ""(空字符串), "a", "aa", "aaa" 等。
这是它的 NFA 片段:
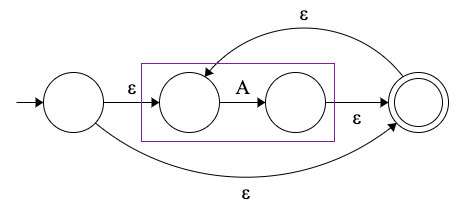
空字符串由最底层的 ε-transition 来接收,而 “更多” 的情况则是通过从接受状态中取回 ε-transition 来处理,并根据需要消耗 A 。
这是在 NFA 正则表达式实现中用来构建其他一切的 5 个基本片段。
注:从我们上面使用的基本块构建 NFAs 的方法被称为汤普森结构。
正则表达式转换到 NFA 示例
现在,当我们知道任何复杂的复合正则表达式都只是由这 5 个基本的 NFA 片段建立起来的,让我们举一个包含所有子片段的例子,看看如何将这个正则表达式翻译成一个合适的 NFA。
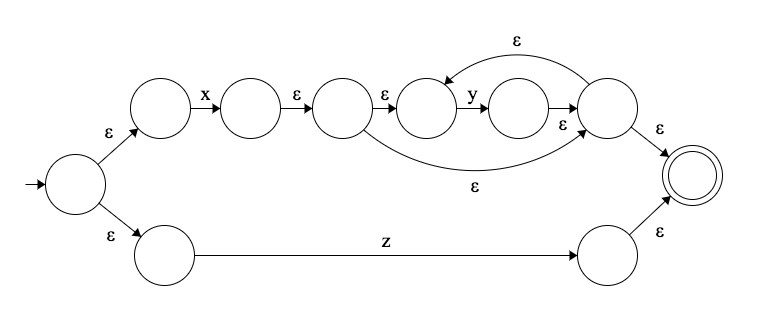
我们的例子是:/xy*|z/ 。
就像我们说的,我们要把这个复杂的表达式分解在原始片段上,然后把它们连接起来就行了。
要做到这一点,我们必须考虑正则表达式的优先级。最高的优先级是符号本身 — A,然后是 “星形” 运算符 — A*。下一个是连词 — AB。最后(最低的优先级)是联合运算符 — A|B。
我们必须逐个构建机器,从最低的优先级开始,也就是 A|B 异构模式。在我们这里是整个表达式,其中 A 是 xy*,B 是 z。
接下来我们要分解出 xy* 复杂模式,也就是 AB 连接模式 —— 其中 A 是 x,B 是 y*。最后我们提取 y*。
这个表达式的 NFA 结果如下: