自动机理论之正则语法
符号、字母和语言
从计算理论和语言学来看,语言由字符串组成,而字符串又由符号组成,符号又属于某个字母表。
例如,我们可以有一个只包含 a 和 b 两个符号的字母表 ∑。
1 | ∑ = {a, b} |
我们可以用这个字母表生成字符串集:
1 | strings(∑) = {a, aa, b, ab, ba, bba, …} |
在这种情况下,我们有一个无界的字符串集,它是无限的 —— 基于它的 “长度” 属性:我们可以有任何长度的字符串,而这个字符串集在理论上是无限的。
这个 “字符串集” 叫做语言。
通常情况下,虽然语言对它们所接受的字符串施加一些限制(或规则)。
例如,使用相同的字母表,我们可以有一种语言 L ,它只接受 “长度为 2 的字符串”。在这种情况下,我们的集合只包含四个字符串:
1 | L: "strings from ∑ of length 2" |
而 “一个字符串是否属于一门语言” 这个问题就是计算理论,以及形式化语法(formal grammars)的主题。像正则表达式这样的工具(其实也完全可以回答同一个问题 —— 一个字符串是否属于一种语言)就是基于这些语法。
形式语法(Formal grammars)
形式语法正式描述一种语言(“字符串集”),定义其结构。通常,人们可能会发现关于形式化语法的讨论大多与 “解析器”(指上下文无关语法)有关。然而,正如我们很快就会看到的那样,在正则表达式的核心中,同样存在着完全相同的形式化语法,在这种情况下,具体来说,这些形式化语法被称为正则语法。
通常,语法 G 是包含四个元素的元组:
1 | G = (N, T, P, S) |
其中 N 是一组非终结符号,T 是一组终结符号,P 是生产规则(production rules)列表,S 是起始符号。
例如:
1 | S → aX |
在这个语法中,非终结符 N(有时称为变量)的集合是:
1 | N = {S, X} |
Non-terminals 是变量,这意味着它们持有一些其他的值(终结符、非终结符或混合的),可以用它们持有的值来替换。在上面的例子中,我们说非终结符 S “可以被替换为” aX,非终结符 X 可以被终结符 b 替换。
相比之下,终结符是无法进一步替换的东西,在我们的字符串中 “原样” 出现。我们终结符的集合 T 包括:
1 | T = {a, b} |
语法的产物(productions)定义了精确的替换规则。我们称它们为派生规则(derivation rules)。所以,产物(production):
1 | S → aX |
可以描述为 “S 可以用 aX 代替”,或者,“S 派生 aX”。
而起始符号(在我们的例子中是 S )是我们开始替换(或衍生)过程的起点。
基本上就是这样:语法的目的是定义一种语言的(可能是递归的)结构 —— 允许像解析器这样的工具根据这个语法来识别(或 “接受”)字符串。
有四种类型的语法,它们在实现时使用不同的技术。例如,上下文无关语法(用于 syntactic analysis,即 “parsers”)使用 push-down automata (PDA),而正则语法则使用 finite automata 作为实现机。
正则语法(Regular grammars)
在形式语法的 Chomsky hierarchy 中,正则语法处定义了最弱的形式语言,即所谓的正则语言。这些语言用正则表达式的概念和符号来表示。
正则语法可能是右线性或左线性,这意味着一个非终结符只能出现在 production 右手侧(right-hand side, RHS)的最右边(通常)或左角。
一个右线性正则语言的示例:
1 | S → aS |
注:ε(Epsilon)是特殊符号,意思是 “空字符串”。
当我们谈论正则表达式时,上面 BNF-notation 中的语法可能看起来不是很熟悉,然而事实上,它直接对应于下面的正则表达式符号。
1 | a*bc* |
注意:语法上正则语法通常用正则表达式符号描述,而不是用 BNF 表示法描述,尽管在幕后使用了完全相同的形式。
与状态机的关系
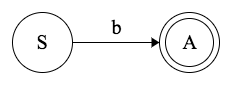
谈起状态机(NFAs 和 DFAs)的实现上,我们看到,正则语法正好定义了有限自动机的状态转换。例如:
1 | S → bA |
第一条 production 说明:“如果我们在状态 S 中,并接收到符号 b,我们应该转到状态 A ”。在这种情况下,epsilon 规则对应的是接受状态。
只能在右 / 左角使用一个非终结符的功能仍允许构建递归规则,但是不能嵌套规则。
递归语法与嵌套语法的比较
关于正则语言,有时会对语法的 “递归” 与 “嵌套” 属性产生误解(导致对正则表达式 “不能处理递归” 的错误理解)。
正则语法无法处理的一个典型例子是 “平衡括号的检查”:
1 | ((())) |
(试着用一个正则表达式来匹配,而不需要追踪一个额外的状态!)
相比之下,这种语言的上下文无关语法就显得非常不重要了。
1 | S → (S) |
然而,正如我们上面所指出的,正则语法只能有一个非终结符,而且只能在 production 的最右边/左边。而在 S → (S) 中,我们的非终结符 S 在 RHS (right-hand side) 的中间。
这个属性 —— 可以把非终结符放在任何地方,而不仅仅是放在最右 / 最左端 —— 定义了语言的嵌套,不应该与通用递归相混淆,通用递归通常由正则语法所支持,如上面例子中的 S → aS 规则。
非常规的正则表达式实现
但请注意,一些现代的正则表达式实现通常支持均匀嵌套。
例如,检查均衡括号的正则表达式是:
1 | ^(\((?1)*\))(?1)*$ |
然而,这种正则表达式机器的实现超越了常规语法。它应该支持嵌套状态,因此已经是一种上下文无关的语言,具有(较慢的)push-down automation,而不是 finite state machine (FSM)。
因此,我们应将正则语法(正则语言)与正则表达式的实现区分开来,对于嵌套这样的复杂情况,正则语法不能使用 FSM 来实现。
附:Chomsky 文法分类体系
0 型文法 (Type - 0 Grammar)
- 无限制文法 (Unrestricted Grammar) / 短语结构文法 (Phrase Structure Grammar, PSG)
- $\forall \alpha \rightarrow \beta \in P$ , $\alpha$ 中至少包含 1 个非终结符
1 型文法 (Type - 1 Grammar)
- 上下文有关语法 (Context-Sensitive Grammar, CSG)
- $\forall \alpha \rightarrow \beta \in P$ , $\left| \alpha \right| \leq \left| \beta \right| $ (即 $\alpha$ 中符号的个数不能多余 $\beta$ 中符号的个数)
- 产生式的一般形式: $\alpha_1 A \alpha_2 \rightarrow \alpha_1 \beta \alpha_2 (\beta \neq \varepsilon )$
- CSG 中不包含 $\varepsilon$ - 产生式
2 型文法 (Type - 2 Grammar)
- 上下文无关语法 (Context-Free Grammar, CFG)
- $\forall \alpha \rightarrow \beta \in P$ , $\alpha \in V_{n}$ (即产生式左部必须是非终结符)
- 产生式的一般形式:$A\rightarrow \beta $
3 型文法 (Type - 3 Grammar)
- 正则文法 (Regular Grammar, RG)
- 右线性 (Right Linear) 文法:$A\rightarrow wB$ 或 $A\rightarrow w$
- 左线性 (Left Linear) 文法:$A\rightarrow Bw$ 或 $A\rightarrow w$
- 左线性文法和右线性文法都称为正则文法