NFA 到 DFA 的转换
NFA 表
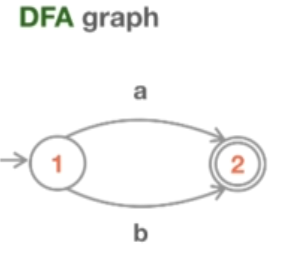
先从一个简单的 Union 举例开始,即 “a 或 b” 表达式。这个机器只接受两个字符串,要么是字符串 “a”,要么是字符串 “b”。获取 NFA 表的算法的第一步是构造实际的 NFA 机,也就是 NFA 图。所以,这是一个含有六个状态的机器,能够同样进入到两个子机器,并从这些子机器中退出。
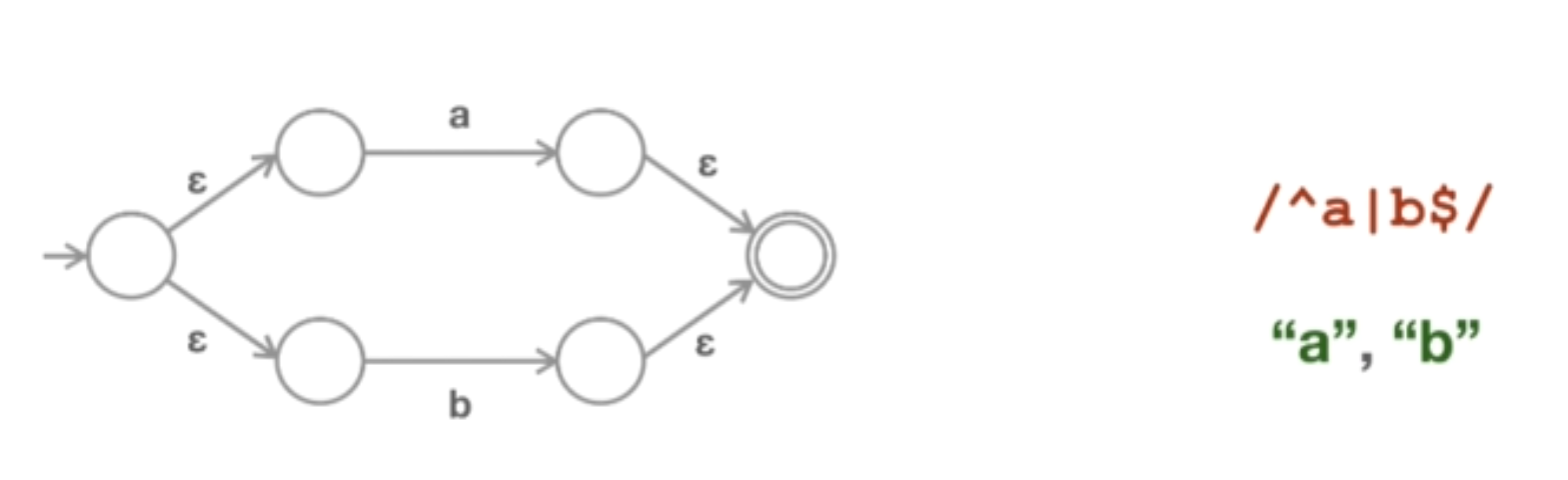
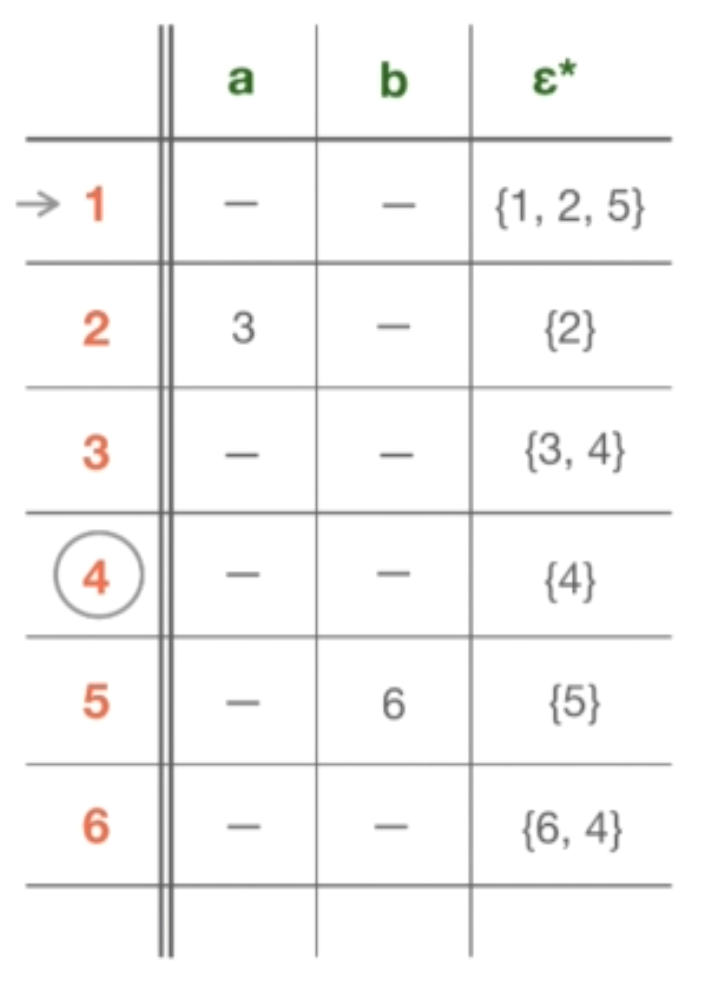
到目前为止,我们只是通过遍历这个图来处理状态节点本身。但是对于表,我们需要实际地给这些状态打上标签。我们可以通过遍历图并使用数字或字母对状态进行标注,如下图所示。
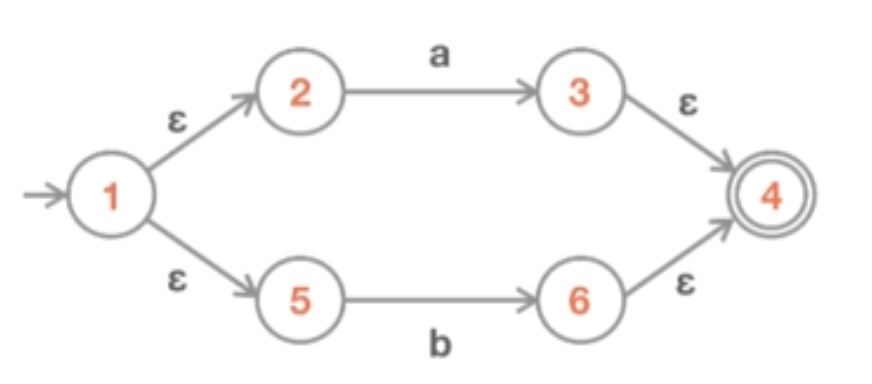
现在我们可以开始把图转换成 NFA 表。表中的行将是我们刚刚分配的状态标签。而列是我们机器的字母表中的所有符号。也就是这个 NFA 的转换边(transition edges)使用的所有符号。在当前的情况下,我们只有两个符号 “a” 和 “b”。
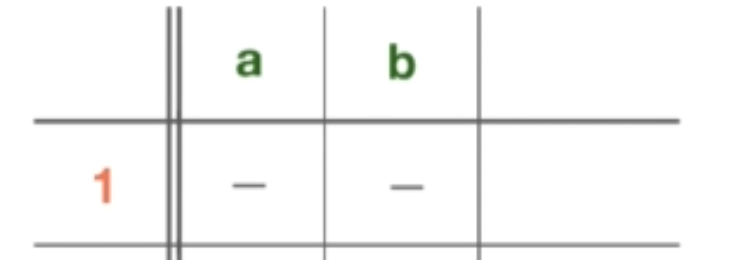
接下来需要实际填表。要做到这一点,只需要查看去哪个位置为一个特定的状态消耗一个特定的字符。例如,从 NFA 图中的状态 1 开始,我们在字符 “a” 和 “b” 上没有任何转换。所得到的只是两个 Epsilon 转换,但 Epsilon 并不是一个真正的符号,所以在表格中,只是表示从状态 1 上的 “a” 和 “b” 都没有去任何地方。也就是说,这些转换从状态 1 出发是非法的。
那状态 2 呢?实际上,状态 2 确实对字符 “a” 进行了转换,然后转到状态 3。我们将其放入表格中行和列的适当交点。但是同时我们在状态 2 上并没有字符 “b” 相关转换,所以它是空的。
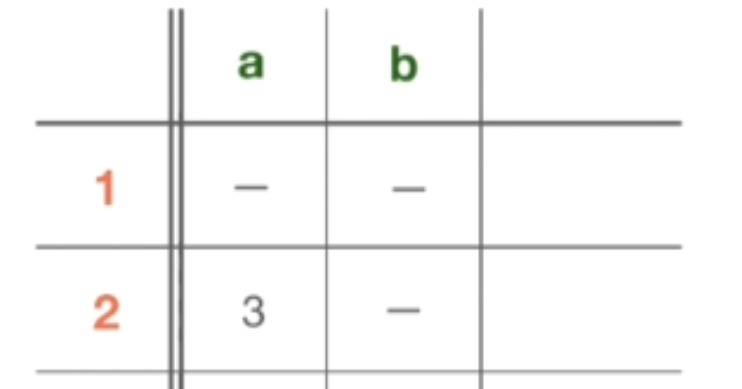
同样的,没有 “a” 或 “b” 从状态 3 的转换。在状态 4 中,没有任何转换。在状态 5 中,没有字符 “a” 的转换,但有一个字符 “b” 的转换,之后进入状态 6。最后,状态 6 和状态 3 相似。
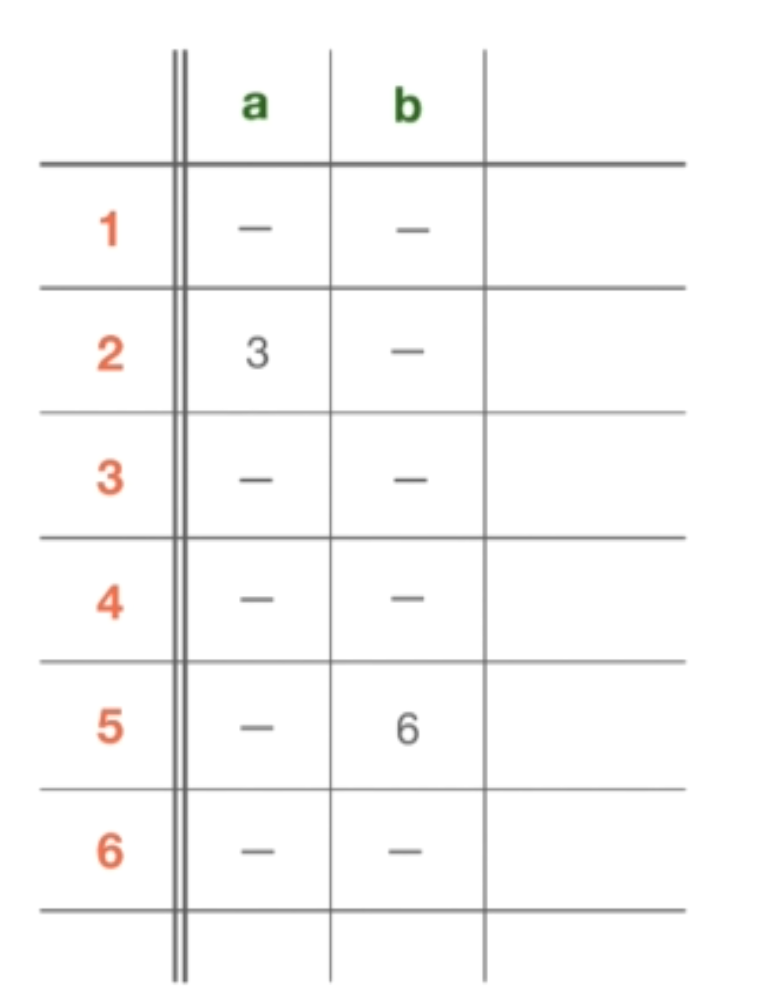
字母表的列已经完成了,但是我们还有一个特殊的转换类型来处理 Epsilon 转换。
该如何在表中表示可以从状态 1 同时进入状态 2 和状态 5 呢?为此要计算所谓的 Epsilon 闭合。它表示为 ε* (Epsilon star),类似于 Kleene 闭合,我们知道,Kleene 闭合是将一个机器重复 “零或更多” 次,同样的 Epsilon 闭合意味着 “零或更多的 Epsilon 转换”,直到它到达一个没有任何 ε-transition 的状态。
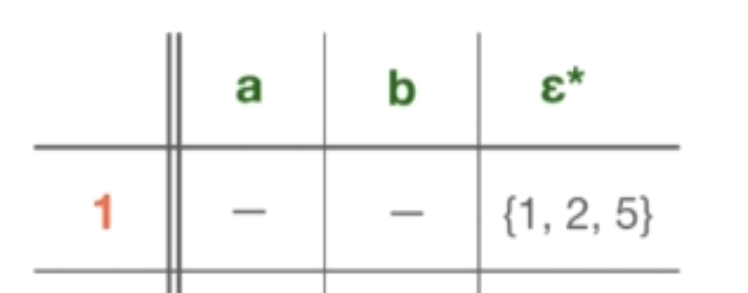
所以,一个特定状态的 ε 闭合,以状态 1 为例 —— 是一组状态。它包括:首先,状态本身,因为我们可以对其应用 Epsilon 转换来达到状态本身。也就是说,将只停留在状态本身,而不消耗任何字符。还有所有其他的状态,我们可以从这个状态出发,只用 ε 转换就可以到达。因此,从状态1中,按照 ε-transition,我们也可以到达状态 2 和状态 5。因为这些状态 1,2 和 5,都没有进一步的 ε-transition,所以没法按照 ε-transition 到达其他的状态。因此状态 1 的 ε 闭合计算就完成了。我们只需将其写入表格的 ε*(Epsilon 闭合)列下。当我们要把这个 NFA 表转换成 DFA 表的时候,需要计算 Epsilon 闭合来消除 ε-transition。同时因为 DFA 不允许 ε-transition,所以在这种情况下,Epsilon 闭合将起到帮助。
同样的,需要计算所有其他状态的 Epsilon 闭合。所以,状态 2 的 ε 闭合包括:状态本身,也就是 2。状态 3 的 Epsilon 闭合是状态本身,也就是 3,同时也有一个 Epsilon 转换到状态 4。所以,总共是 3 和 4。对于状态 4 只是状态本身。同样对于状态 5 也只是它本身。而对于状态 6:除了自身之外,也有一个明确的转换到状态 4。再次,为什么总是把状态本身加入到 Epsilon 闭合中呢?因为这和有 ε 转换到自身是一样的,语义也会一样。所以,我们认为这隐含 ε-过渡。所以此时,NFA 表的计算就完成了。最后,需要在表中表示起始状态,也就是状态 1,以及接受状态,也就是状态 4。
DFA 表
DFA 表的列也包含了机器的字母表,然而并没有 Epsilon 列,因为 DFA 根本不允许 ε 转换。所以,只有 “a” 和 “b” 列。现在需要确定什么将是 DFA 表中的起始状态,因为我们需要从某个地方开始。
那么,起始状态是否应该和 NFA 中一样,也就是状态 1?然而,这行不通,因为状态 1 有 ε-转换,而 DFA 不允许它们。如果能从 NFA 中取出起始状态,并消除所有的 ε-过渡,会怎么样呢?为了消除 ε-转换,我们只需要追踪它们,直到到达一个没有 ε-转换的状态。所以,从状态 1 开始,按照 ε-转换,到达状态 2 和状态 5。现在,当我们确定了这些 Epsilon 转换后,可以通过将这三个状态合并成一个新的状态来消除它们。而这个新的组合状态就是在 DFA 中的起始状态。其实这个组合状态只不过是状态 1 的 Epsilon 闭合,而这正是 NFA 表中这个 ε-closure 列的目的:它允许我们确定 DFA 中的下一个状态,因为我们需要消除那些 ε-转换。综上所述,这就是我们在 DFA 中的起始状态,不过与 NFA 相比,它已经不是一组状态,而只是一个状态标签。
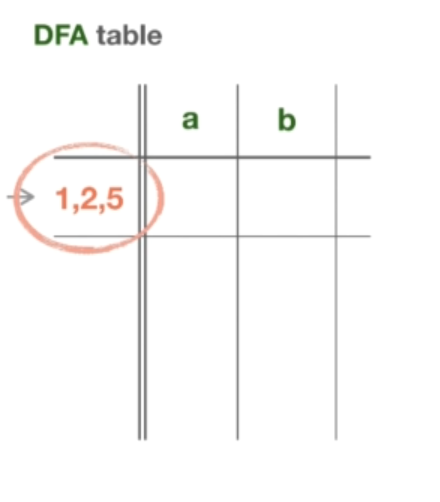
我们把这个状态命名为一个逗号分隔的字符串:“1, 2, 5”。这种算法称为 Subset 构造。也就是说,我们从 NFA 中的多个状态中构造出一个 DFA 状态。现在已经确定了起始状态。我们来给出 DFA 中起始状态的正式定义:DFA 的起始状态是 NFA 起始状态的 Epsilon-closure。现在我们需要看看从这个新的 DFA 状态在 “a” 和 “b” 上的走向。
那么,因为我们在状态 1 的字符 “a” 上没有转换,那里只有 ε-tradition。所以,我们进入下一个状态,状态 2。在状态 2 中,我们在字符 “a” 上有一个转换,并且由它进入状态 3。但同时我们需要消除 ε 转换,为此使用的方法和我们对起始状态的方法完全一样,即取这个状态的 ε-闭合。而状态 3 的 ε-闭合度就是在表中可以看到的,状态 {3,4}。所以,如果要在 NFA 表中看,就像一个之字形。而这就是我们在 DFA 中的新状态 —— 状态为 {3, 4}。由于状态 5 没有字符 “a” 的转换,所以从起始状态开始的字符计算就完成了。
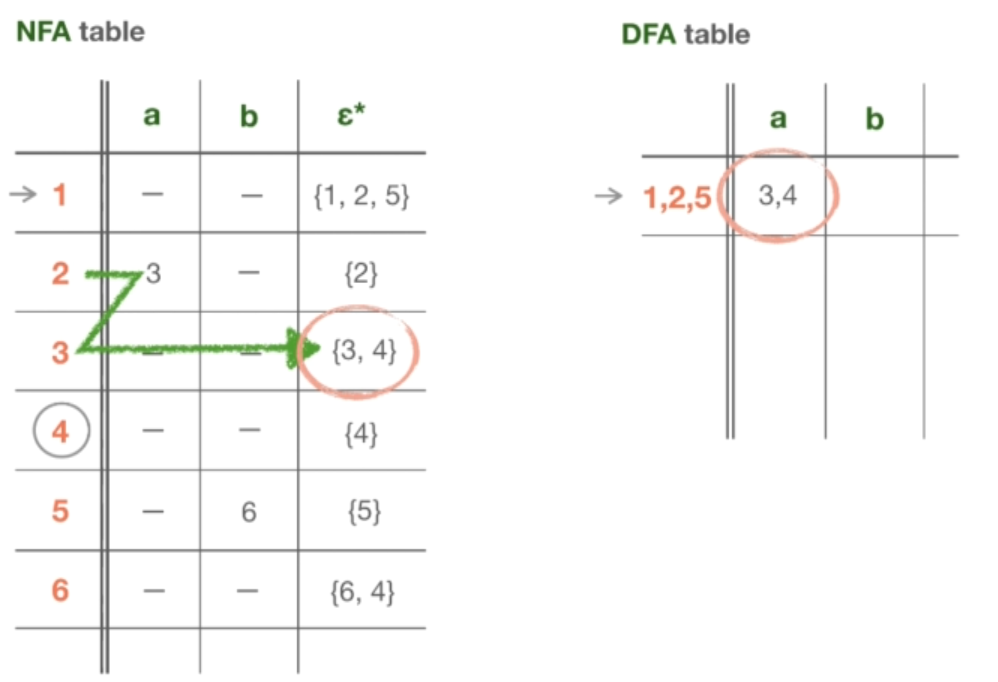
现在说明如何计算一个特定字符的 DFA 转换的正式定义。如果在 DFA 中出现了一个新的状态 "X, Y, Z"(在我们的例子中是 {1, 2, 5} ),那么为了计算从这个状态到某个特定字符的位置,我们应该确定从 NFA 中的每个状态的去向,并应用 Epsilon-closure 以消除 ε-转换。

现在来完成剩下的转换。所以,我们从 NFA 中的状态 1 的 “b” 去到哪里?没有地方。我们从状态 2 的 “b” 去哪里?没有地方。 那我们从状态 5 的 “b” 去哪里呢?在这里,我们是到达了状态 6,为了消除 ε 转换,我们从状态 6 出发,沿着它们走,这就得到了下一个新的状态,而这无非又是状态 6 的 ε-闭合,也就是 {6, 4}。
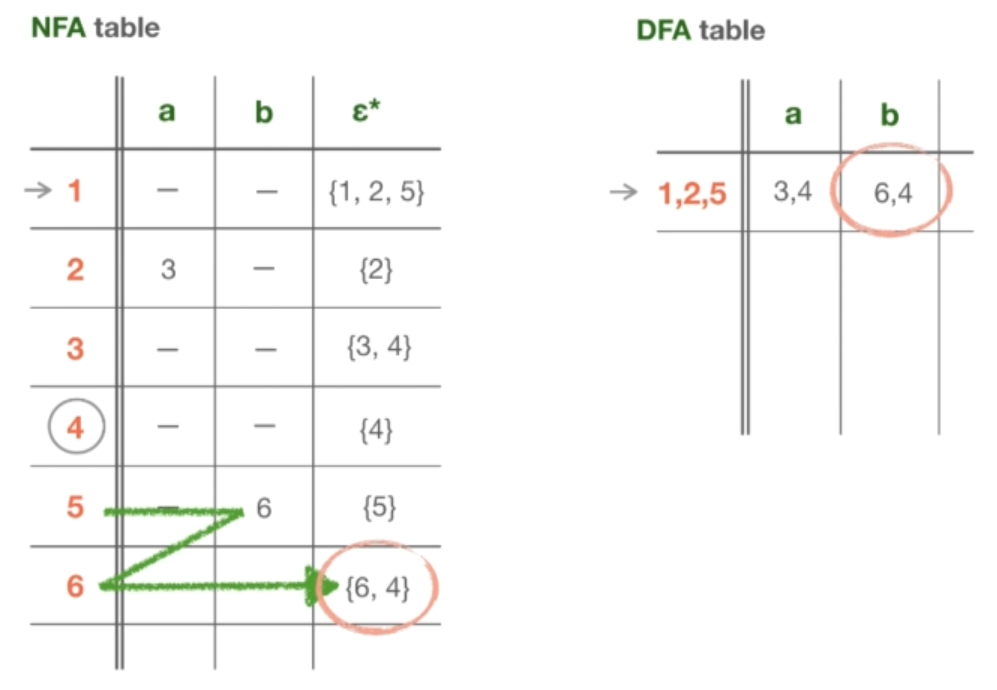
现在已经确定了 “a” 和 “b” 的起始状态的走向。然而,这还没有结束。由于我们引入了两个新的状态,即 {3, 4} 和 {6, 4},我们必须将它们添加到表中,并对每个新状态重复整个操作。首先处理 {3, 4} 这个状态。幸运的是,对字符 “a” 没有任何转换:既没有从状态 3 中转换,也没有从状态 4 中转换,也就是说,我们不会从状态 {3, 4} 的任何地方去处理字符 “a”。而对于字符 “b “来说也完全一样,既没有从状态 3,也没有从状态 4 的转换,所以我们也在字符 “b” 的表格中填入 “无”。
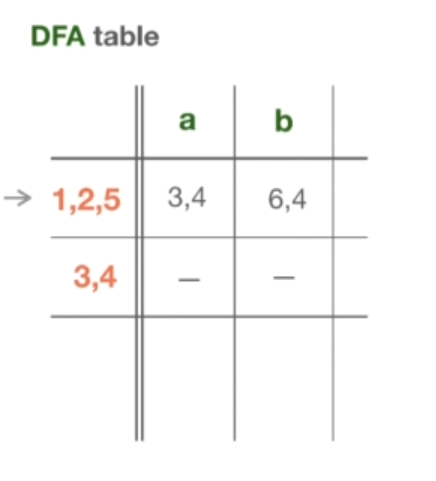
现在是下一个状态,{6, 4}。在这里同样是幸运的,因为既没有 “a” ,也没有 “b” 的转换。此时我们还没有引入任何新的状态,所以 DFA 表的计算就完成了。其实还有最后一件事:我们需要确定 DFA 中的接受态是什么。所谓的接受状态,或者说 DFA 中的接受状态,是指任何包含 NFA 中的接受状态的东西。NFA 中的接受状态是 4,我们可以看到这两个状态都包含了状态 4,所以它们在 DFA 中都是接受状态。如果说在 NFA 中我们有一个不变性,即永远只有一个起始状态,只有一个接受状态,那么在 DFA 中我们可以有多个接受状态。现在可以说 DFA 表的构造已经完成了。
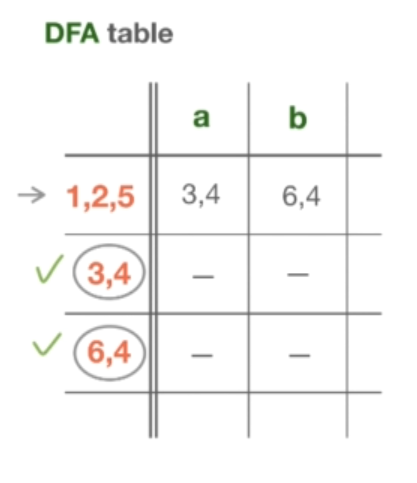
DFA 最小化
在自动机理论中,还有一个 DFA 最小化的过程,这可以获得一个更小更快的机器。现在我们只需观察一下,状态 {3, 4} 和状态 {6, 4} 实际上是相同的。在 DFA 最小化算法中,这两个状态,正如我们将很快看到的那样,被称为彼此 0-等价(0-equivalent)。在这种情况下,这两个状态可以合并为一个单一的状态,对实际状态标签重命名后的结果如下图所示。

现在来详细了解一下我们到底是如何获得这个最小版本的 DFA 的。为此我们以下面的 DFA 为例。
我们有状态 1,通过字符 “a” 进入状态2,通过字符 “b” 上会进入状态 3。而状态 2 上通过字符 “a” 将回到自身,而通过字符 “b”,我们将进入状态 4。从状态 4 我们通过字符 “a” 回到状态 2,通过字符 “b” 进入状态5。从状态 5 上的 “a” 我们回到状态 2,通过字符 “b” 回到状态 3。最后,从状态 3 上的字符 “a”,我们进入状态 2,通过 “b” 回到自身。这就是最初的 DFA。
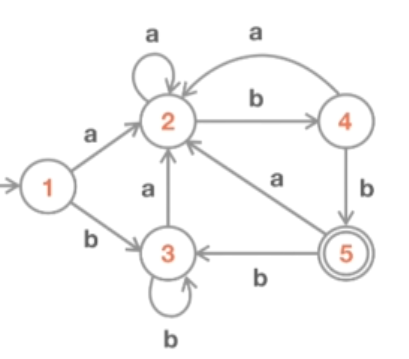
是不是最小化现在无法看出来。但是可以看出,状态 1 和状态 3 其实是等同的:它们都不是最终状态;通过字符 “a” ,它们都进入状态 2;通过字符 “b”,它们都进入状态 3。现在我们来看看具体如何确定这两个状态其实是相等的。首先,我们应该说,状态 q1 和 q2 是等价的,如果它们意味着以下几点:如果从状态 q1 消耗任意字符串 s,我们进入某个最终状态,如果从状态 q2 消耗同样的字符串 s,也会发生同样的情况 —— 这些状态是等价的,可以合并。或者,如果这两个状态消耗的仍然是同一个字符串 s,进入某个非最终状态,它们也是等价的。现在,如果字符串 s 的长度为 0,我们称这种状态为 0-等价,如果长度为 1,则这些状态之间为 1-等价,以此类推。如果长度为 n,则称这些状态为 n-等价。
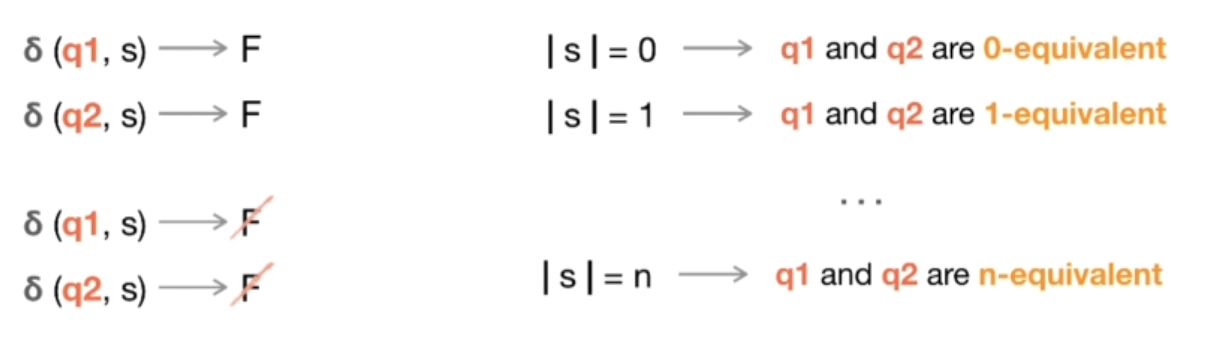
为了让这个理论定义更加清晰,我们来检测刚才的例子。等价算法从把所有的状态分成两组开始。第一组包含所有非接受状态,而第二组包含所有的最终状态。在我们的例子中,唯一的最终状态是状态号 5。所以它在第二组。所有其他的状态都在第一组中。而每组中的状态彼此之间都是 0-等价的。因为通过消耗一个空字符串,也就是零长度的字符串,我们保持在同一个状态。

现在我们需要看看这些状态之间是否是 1-等价的。让我们从状态 1 和 2 开始,为了检查它们是否相等,应该看看每个字符从这些状态去到哪里。如果去到属于同一组的状态,那么原来的状态是相等的。所以,状态 1 通过字符 “a” 去到状态2。而同样状态 2 通过字符 “a” 回到自身,所以状态 1 和 2 属于同一组。但我们还需要检查 “b” 这个字符的转换。状态 1 通过 “b” 进入状态3,但状态 2 通过 “b” 实际上进入状态 4,两者实际状态是不同的。然而重要的是去往的状态是否属于同一组。在这种情况下,状态 3 和状态 4 属于同一组(都属于 0-equivalence),所以状态 1 和状态 2 是 1-等价的。在这种情况下,我们又把它们放在同一个新的组中。

现在我们要看状态 3 与状态 1 和状态 2 是否是 1-等价的。因为状态 1 和 2 是等价的,所以我们不能将状态 3 与其中任何一个状态进行等价比较。我们以状态 2 为例,通过字符 “a” ,两个状态都去到相同的状态 2。而在字符 “b” 上,状态 2 去到状态 4,状态 3 回到自身,同理由于 3 和 4 都在同一组(0-equivalence),所以状态 2 和 3 是 1-等价的。因此我们把状态 3 与状态 1 和 2 放在同一组。我们现在再进一步检查一下状态 4,把它和状态 3 比较一下。通过字符 “a”,一切正常,我们进入了相同的状态 2。但是通过字符 “b”,状态 3 回到自身,状态 4 进入到状态 5,状态 3 和状态 5 实际上是在不同的组(0-equvialence)中,所以状态 4 与状态 1、2 和 3 不等价。为此我们为状态 4 分配一个新的组。至此,1-等价的计算就完成了。

我们现在需要继续计算这些状态的 2-等价性。我们只需重复之前方法,但现在我们要比较的是第二行(1-equivalence)的状态是否属于同一组,而不是第一行的状态。让我们再检查一下状态 1 和状态 2,看看它们之间是否是 2-等价的。通过字符 “a” ,我们进入了相同的状态 2。但是通过字符 “b” 进入了不同的状态 3 和 4,现在属于不同的组(1-equivalence)。所以,我们得出结论,状态 1 和状态 2 之间不是 2-等价的。为此我们再次为状态 2 分配一个新的组,现在我们需要检查状态 3。对于状态 3,通过 “a” 和 “b” 这两个字符进入了状态 2 和状态 3,这两个字符在同一个组中(1-equivalence),所以状态 1 和状态 3 是 2-等价的。

再进一步看看状态 1 和 3 是否为 3-等价的。通过 “a” 和 “b” 这两个字符,马上判断出状态 1 和 3 是 3-等价的。因为到了这一步还没有引入新的组,所以算法就完成了。

由此我们来绘制最小 DFA 的表格与图。
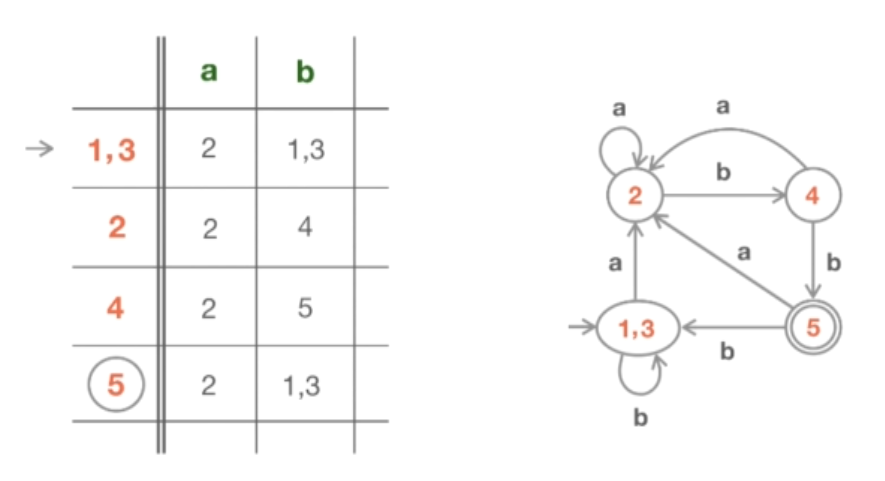
最后,让我们回到最初的 a|b 模式的例子。同样,我们将最初所有的状态分成两组:非接受和接受。而计算状态的 1-等价性,也得到了同样的结果。所以状态 2 和状态 3 是等价的,可以合并。

重命名后,表中的结果看起来是这样的只有两个状态。再对比一下原来的 NFA 图和表。在这种情况下,DFA 表变得更小更快。