使用 PyTorch 实现 Transformer 结构(一):多头注意力机制
我计划通过几篇文章来整理一下如何使用 PyTorch 实现 2017 年《Attention is all your need》论文中的 Transformer 模型结构。关于 Transformer 的理论部分网络上已经有非常多的文章或视频讲解,如果你想要了解这部分的内容,我个人比较推荐的是来自图灵出版社公众号的一篇文章:《一文读懂 Transformer,工作原理与实现全解析》。
准备
在使用 PyTorch 编写模型结构前,通常会先初始化一些基本环境配置。
1 | import torch |
此外让我们先初始化 Transformer 模型的一些结构参数。
1 | d_model = 512 # embedding size |
Scaled Dot-Product Attention
Transformer 的核心是多头注意力机制,在实现多头注意力机制之前,需要先实现缩放点积注意力(Scaled Dot-Product Attention)。
实现缩放点积注意力其实就是实现公式 $\text{Attention(Q, K, V)}=\text{softmax}(\frac{QK^T}{\sqrt{d_k}})V$,也就是下面这张图:
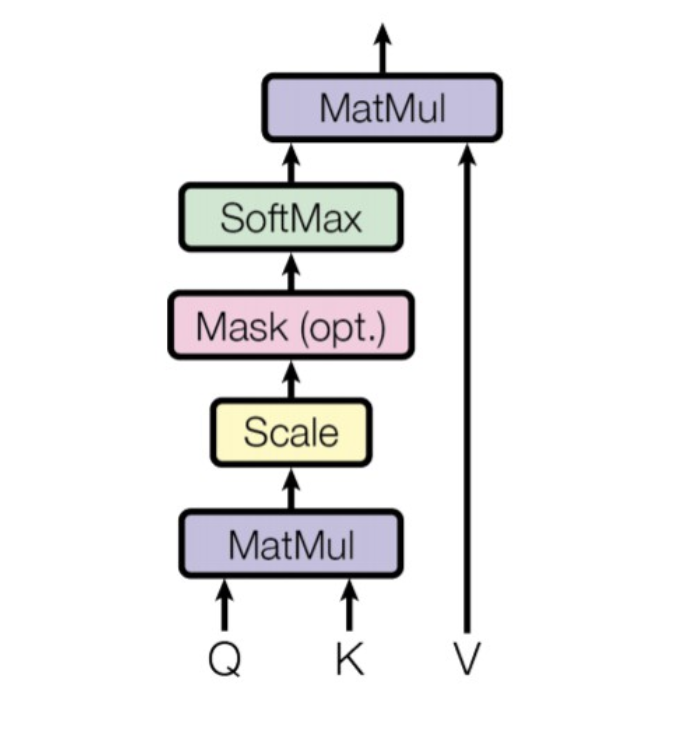
我们可以把缩放点积注意力当成一个方法来实现:
1 | def scaled_dot_product_attention( |
上述代码中:
@等价于torch.matmul()- 除以 $\sqrt{d_k}$ 是为了缩放点积的结果,防止其数值过大导致梯度消失,从而稳定训练过程
- 使用负无穷大作为掩码值是因为:
- softmax 函数形式为 $\text{softmax}(z)_i = \frac{e^{z_i}}{\sum^K_{j=1} e^{z_j}}$
- 当 $x$ 趋向负无穷大时,指数函数 $e^x$ 趋向于 0
- 那么想要掩盖掉第 $k$ 个位置,就将值设置为无穷大,从而在计算 softmax 时第 $k$ 个位置对应的分子会趋近于 0 ,因此 softmax 输出为 0
Multi-Head Attention
上述缩放点积注意力是对单个头进行计算,接下去让我们来实现多头注意力机制。这部分代码主要就是将模型拆分成多个头,例如 $d_{model}$ 为 512,拆分成 8 个头,则每个头维度为 64。
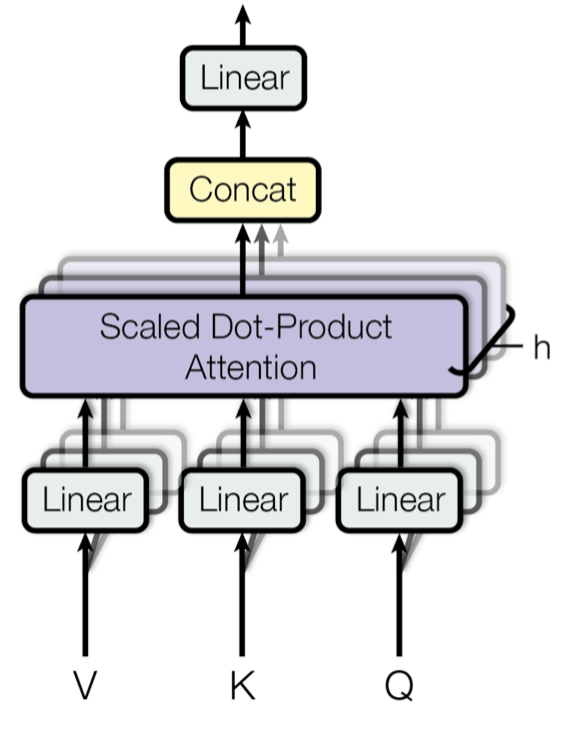
1 | class MultiHeadAttention(nn.Module): |
上述代码中:
bias并不一定要全为False,另外几种常见的配置是把bias全部设置为True或者W_o的bias为True- 可以把
scaled_dot_product_attention()作为静态方法合并到MultiHeadAttention类中
FeedForward Network
前馈神经网络这部分实现起来比较简单,它是一个典型的 MLP。
1 | class FeedForwardNetwork(nn.Module): |