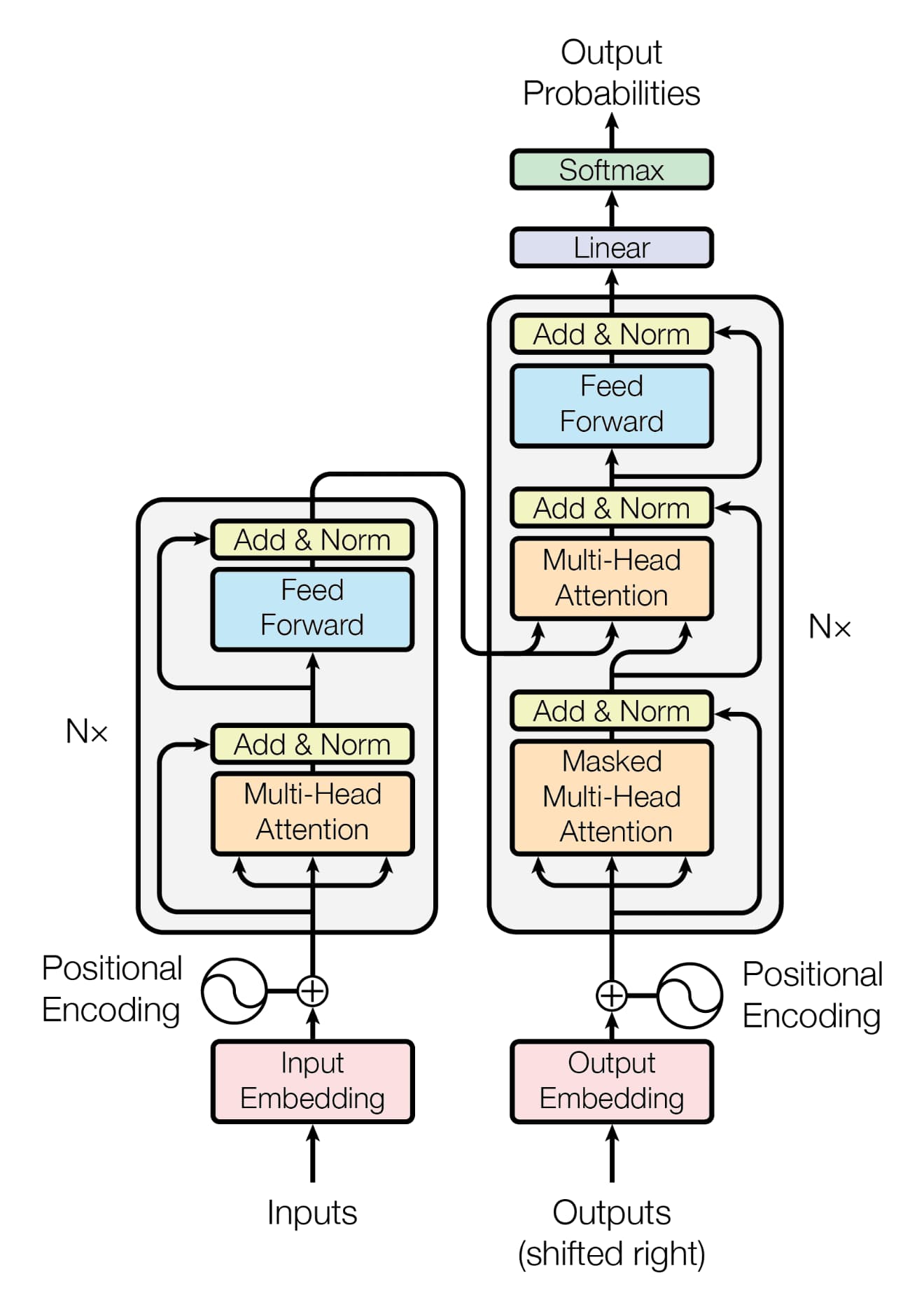
在上一篇文章中已经实现了 Transformer 中核心的缩放点积注意力、多头注意力以及前馈神经网络,那么这篇文章中我们先将这几部分封装成编码器层和解码器层,然后再去实现完整的编码器和解码器。
![Transformer]()
Encoder Block/Layer
首先我们来实现一个基本的编码器模块(层),代码其实很简单,只要额外在 MultiHeadAttention 和 FeedFrowardNetwork 后面加上残差连接和 Layer Normalization 即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| class EncoderBlock(nn.Module):
def __init__(self):
super().__init__()
self.mha = MultiHeadAttention()
self.layer_norm_1 = nn.LayerNorm(d_model)
self.ffn = FeedForwardNetwork()
self.layer_norm_2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(p_drop)
def forward(
self,
x: torch.Tensor,
mask: torch.Tensor | None = None,
):
"""
Args:
x: (batch_size, seq_len, d_model)
mask: Optional mask.
"""
attention_output, _ = self.mha(x, x, x, mask)
x = x + self.dropout(attention_output)
x = self.layer_norm_1(x)
feedforward_output = self.ffn(x)
x = x + self.dropout(feedforward_output)
x = self.layer_norm_2(x)
return x
|
在上述代码中,mask 用于屏蔽输入序列中填充(padding)的部分,防止模型关注到这些无意义的标记。
Decoder Block/Layer
解码器模块(层)实现会比 EncoderBlock 略微复杂一些,因为多了一个带掩码的 Multi-Head Attention 以及需要处理 Cross Attention。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
| class DecoderBlock(nn.Module):
def __init__(self):
super().__init__()
self.mha_1 = MultiHeadAttention()
self.layer_norm_1 = nn.LayerNorm(d_model)
self.mha_2 = MultiHeadAttention()
self.layer_norm_2 = nn.LayerNorm(d_model)
self.ffn = FeedForwardNetwork()
self.layer_norm_3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(p_drop)
def forward(
self,
x: torch.Tensor,
encoder_output: torch.Tensor,
src_mask: torch.Tensor | None = None,
tgt_mask: torch.Tensor | None = None,
):
"""
Args:
x: Target sequence embedding, (batch_size, target_seq_len, d_model)
encoder_output: Output from encoder, (batch_size, source_seq_len, d_model)
src_mask: Mask for source padding in encoder_output.
tgt_mask: Mask for target sequence (self-attention). Combines look-ahead and padding.
"""
attention_output_1, _ = self.mha_1(x, x, x, tgt_mask)
x = x + self.dropout(attention_output_1)
x = self.layer_norm_1(x)
attention_output_2, _ = self.mha_2(x, encoder_output, encoder_output, src_mask)
x = x + self.dropout(attention_output_2)
x = self.layer_norm_2(x)
feedforward_output = self.ffn(x)
x = x + self.dropout(feedforward_output)
x = self.layer_norm_3(x)
return x
|
上述代码中:
tgt_mask 作用于第一个多头注意力层,即解码器的 Masked Multi-Head Attention。
- 它通过将注意力分数矩阵中对应于未来位置的部分设置为负无穷大(这通常是一个上三角矩阵,对角线以上为 True/1,表示屏蔽),从而使这些位置的注意力权重趋近于 0,来防止模型看到未来信息。
- 同时也会屏蔽目标序列中的填充标记。
src_mask 作用于第二个多头注意力层,即解码器的 Cross Attention,目的就是屏蔽编码器输出中的填充部分。
位置编码
在实现 Encoder 和 Decoder 之前,需要先实现位置编码。Transformer 中使用了正弦位置编码,我们需要实现如下两个公式:
$$
\text{PE}(pos, 2i) = \sin\left(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}}\right)
$$
$$
\text{PE}(pos, 2i+1) = \cos\left(\frac{pos}{10000^{\frac{2i}{d_{\text{model}}}}}\right)
$$
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| class PositionalEncoding(nn.Module):
def __init__(self):
super().__init__()
pe = torch.zeros(max_len, d_model, device=device)
position = torch.arange(0, max_len, device=device).float().unsqueeze(1)
indices_2i = torch.arange(0, d_model, 2, device=device).float()
div_term = torch.pow(10000.0, -indices_2i / d_model)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer("pe", pe.unsqueeze(0))
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Args:
x: (batch_size, seq_len, d_model)
"""
return x + self.pe[:, : x.size(1), :]
|
Encoder
在完成绝对位置编码之后,就可以实现 Encoder 了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| class Encoder(nn.Module):
def __init__(self, vocab_size: int):
super().__init__()
self.embeddings = nn.Embedding(vocab_size, d_model)
self.pe = PositionalEncoding()
self.dropout = nn.Dropout(p_drop)
self.encoder_blocks = nn.ModuleList([EncoderBlock() for _ in range(n_layers)])
def forward(self, x: torch.Tensor, mask: torch.Tensor | None = None):
"""
Args:
x: 输入的 token IDs, 形状为 (batch_size, seq_len)。
mask: Padding mask for the source sequence.
"""
x = self.embeddings(x)
x = self.pe(x)
x = self.dropout(x)
for block in self.encoder_blocks:
x = block(x, mask)
return x
|
Decoder
Decoder 的实现和 Encoder 几乎一致。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| class Decoder(nn.Module):
def __init__(self, vocab_size: int):
super().__init__()
self.embeddings = nn.Embedding(vocab_size, d_model)
self.pe = PositionalEncoding()
self.dropout = nn.Dropout(p_drop)
self.decoder_blocks = nn.ModuleList([DecoderBlock() for _ in range(n_layers)])
def forward(
self,
x: torch.Tensor,
encoder_output: torch.Tensor,
src_mask: torch.Tensor | None = None,
tgt_mask: torch.Tensor | None = None,
):
"""
Args:
x: Target tokens (IDs), (batch_size, target_seq_len)
encoder_output: Output from encoder, (batch_size, source_seq_len, d_model)
src_mask: Mask for source padding (encoder output).
tgt_mask: Mask for target padding and future positions (target sequence).
"""
x = self.embeddings(x)
x = self.pe(x)
x = self.dropout(x)
for block in self.decoder_blocks:
x = block(x, encoder_output, src_mask, tgt_mask)
return x
|