Syntax Analysis
自顶向下分析概述
- 从分析树的顶部(根节点)向底部(叶节点)方向构造分析树
- 可以看成是从文法开始符号 S 推导出词串 $w$ 的过程
最左推导(Left - most Derivation)
- 在最左推导中,总是选择每个句型的最左非终结符进行替换
- 如果 $S\Rightarrow^{\ast} {}_{lm}\alpha$ ,则称 $\alpha$ 是当前文法的最左句型(left-sentential form)
最右推导(Right - most Derivation)
- 在最右推导中,总是选择每个句型的最右非终结符进行替换
- 在自底向上的分析中,总是采用最左归约的方式,因此把最左归约称为规范归约 ,而最右推导相应地称为规范推导 。
通用形式
- 递归下降分析(Recursive - Descent parsing)
- 由一组过程组成,每个过程对应一个非终结符
- 可能需要回溯 (backtracking) ,导致效率较低
- 预测分析(Predictive Parsing)
- 预测分析是递归下降分析技术的一个特例,通过在输入中向前看固定个数(通常为 1)符号来选择正确的 A - 产生式
- 可以对某些文法构造出向前看 k 个输入符号的预测分析器,该类文法有时也称为 LL(k) 文法类
- 预测分析不需要回溯,是一种确定的自顶向下分析方法
文法转换
问题
- 同一非终结符的多个候选式存在共同前缀,将导致回溯现象
- 含有 $A\rightarrow A\alpha$ 形式产生式的文法称为是 直接左递归 的(immediate left recursive)
- 如果一个文法中有一个非终结符 A 使得对某个串 $\alpha$ 存在一个推导 $A\Rightarrow ^+A\alpha$ ,那么这个文法就是 左递归 的
- 经过两步或两步以上推导产生的左递归称为是 间接左递归 的
- 左递归文法会使递归下降分析器陷入无限循环
消除直接左递归
$A\rightarrow A\alpha|\beta$ ($\alpha \neq \varepsilon$ , $\beta$ 不以 A 开头) (用正则表示为:$r=\beta\alpha^\ast$ )
$\Rightarrow$
$A\rightarrow \beta A’$
$A’ \rightarrow \alpha A’ |\varepsilon$
这种消除过程就是把 左递归 转换成了 右递归
消除直接左递归的一般形式
$A \rightarrow A\alpha_1|A\alpha_2|\ldots|A\alpha_n|\beta_1|\beta_2|\ldots|\beta_m$ ($\alpha_i \neq \varepsilon$ , $\beta_j$ 不以 A 开头)
$\Rightarrow$
$A \rightarrow \beta_1A’|\beta_2A’|\ldots|\beta_mA’$
$A’ \rightarrow \alpha_1A’|\alpha_2A’|\ldots|\alpha_nA’|\varepsilon$
消除左递归需要付出代价 $\rightarrow$ 引进了一些 非终结符 和 $\varepsilon$-产生式
消除间接左递归
$S \rightarrow A\alpha | b, A \rightarrow Ac|Sd|\varepsilon$
将 S 的定义带入 A - 产生式,得:
$A \rightarrow Ac|Aad|bd|\varepsilon$
消除 A - 产生式的直接左递归,得:
$A \rightarrow bdA’|A’$
$A’ \rightarrow cA’|adA’|\varepsilon$
提取左公因子(Left Factoring)
$S \rightarrow aAd|aBe$
$\Rightarrow$
$S \rightarrow aS’$
$S’ \rightarrow Ad|Be$
通过改写产生式来推迟决定,等读入了足够多的输入,获得足够信息后再做出正确的选择
LL(1) 文法
S_文法
- 预测分析法的工作过程:
从文法开始符号处罚,在每一步推导过程中根据当前句型的最左非终结符 A 和当前输入符号 $\alpha$ ,选择正确的 A - 产生式。为保证分析的正确性,选出的候选式必须是唯一的。 - S_文法:
- 每个产生式的右部都以终结符开始
- 同一个非终结符的各个候选式的首终结符都不同
- S_文法不含 $\varepsilon$ 产生式
- 什么时候使用 $\varepsilon$ 产生式?
如果当前某非终结符 A 与当前输入符 $\alpha$ 不匹配时,若存在 $A \rightarrow \varepsilon$ ,可以通过检查 $\alpha$ 是否可以出现在 A 的后面,来决定是否使用产生式 $A \rightarrow \varepsilon$ (若文法中无 $A \rightarrow \varepsilon$ ,则应报错)
非终结符的后继符号集
- 可能在某个句型中紧跟在 A 后边的终结符 $\alpha$ 的集合,记为 FOLLOW(A)
- $FOLLOW(A)={a|S \Rightarrow^\ast \alpha Aa\beta , a \in V_T, \alpha \beta \in (V_T \cup V_N)^\ast}$
- 如果 A 是某个句型的最右符号,则将结束符 “S” 添加到 FOLLOW(A) 中
产生式的可选集
- 产生式 $A \rightarrow \beta$ 的可选集是指可以选用该产生式进行推导时对应的输入符号的集合,记为 SELECT($A \rightarrow \beta$)
- $SELECT(A \rightarrow a\beta) = {a}$
- $SELECT(A \rightarrow \varepsilon) = FOLLOW(A)$
- q_文法
- 每个产生式的右部或为 $\varepsilon$ ,或以终结符开始
- 具有相同左部的产生式有不相交的可选集
- q_文法不含右部以非终结符打头的产生式
串首终结符集
- 串首终结符
串首第一个符号,并且是终结符。简称首终结符。 - 给定一个文法符号串 $\alpha$ ,$\alpha$ 的串首终结符集 FIRST($\alpha$) 被定义为可以从 $\alpha$ 推导出的所有串首终结符构成的集合。如果 $\alpha \Rightarrow^\ast \varepsilon$ ,那么 $\varepsilon$ 也在 FIRST($\alpha$) 中
- 产生式 $A \rightarrow \alpha$ 的可选集 SELECT
- 如果 $\varepsilon \notin FIRST(\alpha)$ ,那么 $SELECT(A \rightarrow \alpha) = FIRST(\alpha)$
- 如果 $\varepsilon \in FIRST(\alpha)$ ,
那么 $SELECT(A \rightarrow \alpha ) = (FIRST( \alpha ) - \lbrace \varepsilon \rbrace ) \cup FOLLOW(A)$
LL(1) 文法
- 第一个 L 表示从左向右扫描输入
- 第二个 L 表示产生最左推导
- 1 表示在每一步中只需要向前看一个输入符号来决定语法分析动作
文法 G 是 LL(1) 的,当且仅当 G 的任意两个具有相同左部的产生式 $A \rightarrow \alpha | \beta$ 满足下面的条件:
- 如果 $\alpha$ 和 $\beta$ 均不能推导出 $\varepsilon$ ,则 $FIRST(\alpha) \cap FIRST(\beta) = \phi$
- $\alpha$ 和 $\beta$ 至多有一个能推导出 $\varepsilon$
- 如果 $\beta \Rightarrow^\ast \varepsilon$ ,则 $FIRST(\alpha) \cap FOLLOW(A) = \phi$
- 如果 $\alpha \Rightarrow^\ast \varepsilon$ ,则 $FIRST(\beta) \cap FOLLOW(A) = \phi$
FIRST 集和 FOLLOW 集的计算
建议去看一遍原视频上的推导过程,或者可以参考上一篇文章。
计算文法符号 X 的 FIRST (X)
例:
1 | E -> TE' FIRST(E) = { ( id } |
计算串 $X_1X_2 \ldots X_n$ 的 FIRST 集合
- 向 $FIRST(X_1X_2 \ldots X_n)$ 加入 $FIRST(X_1)$ 中所有的非 $\varepsilon$ 符号
- 如果 $\varepsilon$ 在 $FIRST(X_1)$ 中,再加入 $FIRST(X_2)$ 中的所有非 $\varepsilon$ 符号;如果 $\varepsilon$ 在 $FIRST(X_1)$ 和 $FIRST(X_2)$ 中,再加入 $RIRST(X_3)$ 中的所有非 $\varepsilon$ 符号,以此类推
- 最后,如果对所有的 i, $\varepsilon$ 都在 $FIRST(X_i)$ 中,那么将 $\varepsilon$ 加入到 $FIRST(X_1X_2 \ldots X_n)$ 中
计算非终结符 A 的 FOLLOW(A)
例:
1 | E -> TE' FOLLOW(E) = { $ ) } |
算法
不断应用下列规则,直到没有新的终结符可以被加入到任何 FOLLOW 集合中为止
- 将
$放入 FOLLOW(S) 中,其中 S 是开始符号,$是输入右端的结束标记 - 如果存在一个产生式 $A \rightarrow \alpha B \beta$ ,那么 $FIRST(\beta)$ 中除 $\varepsilon$ 之外的所有符号都在 FOLLOW(B) 中
- 如果存在一个产生式 $A \rightarrow \alpha B$ ,或存在产生式 $A \rightarrow \alpha B \beta$ 且 $FIRST(\beta)$ 包含 $\varepsilon$ ,那么 FOLLOW(A) 中的所有符号都在 FOLLOW(B) 中
计算表达式文法各产生式的 SELECT 集
例:
1 | E -> TE' SELECT(1) = { ( id } |
自底向上分析概述
- 从分析树的底部(叶节点)向顶部(根节点)方向构造分析树
- 可以看成是将输入串 w 归约为文法开始符号 S 的过程
- 自底向上的语法分析采用 最左归约 方式(反向构造最右推导)
- 自顶向下的语法分析采用最左推导方式
- 自底向上语法分析的通用框架
- 移入 - 归约分析(Shift - Reduce Parsing)
- 每次归约的符号串称为 “句柄(handle)”
- 句柄:句型的最左直接短语
- 栈内符号串 + 剩余输入 = “规范句型”
LR 分析法概述
LR 分析法
- LR 文法是最大的、可以构造出相应 移入 - 归约语法分析器 的文法类
- L:对输入进行从左到右的扫描
- R:反向构造出一个最右推导序列
- LR (k) 分析
- 需要向前查看 k 个输入符号的 LR 分析
k=0和k=1这两种情况具有实践意义;当省略(k)时,表示k=1
LR 分析法的基本原理
关键问题在于如何正确地识别句柄
句柄是逐步形成的,用 “状态” 表示句柄识别的进展程度
例:
$S \rightarrow bBB$
$S \rightarrow ·bBB \quad \leftarrow \quad 移进状态$
$S \rightarrow b·BB \quad \leftarrow \quad 待约状态$
$S \rightarrow bB·B \quad \leftarrow \quad 待约状态$
$S \rightarrow bBB· \quad \leftarrow 归约状态$
LR 分析器基于这样一些状态来构造自动机进行句柄的识别
LR(0) 分析
LR(0) 项目
右部某位置标有圆点的产生式称为相应文法的一个 LR(0) 项目(简称为项目)
$A \rightarrow \alpha_1 · \alpha_2$
项目描述了 句柄识别的状态
产生式 $A \rightarrow \varepsilon$ 只生成一个项目 $A \rightarrow ·$
例:
$S \rightarrow bBB$
$S \rightarrow ·bBB \quad \leftarrow \quad 移进项目$
$S \rightarrow b·BB \quad \leftarrow \quad 待约项目$
$S \rightarrow bB·B \quad \leftarrow \quad 待约项目$
$S \rightarrow bBB· \quad \leftarrow 归约项目$
增广文法 (Augmented Grammar)
如果 G 是一个以 S 为开始符号的文法,则 G 的增广文法 G’ 就是在 G 中加上新开始符号 S’ 和产生式 $S’ \rightarrow S$ 而得到的文法
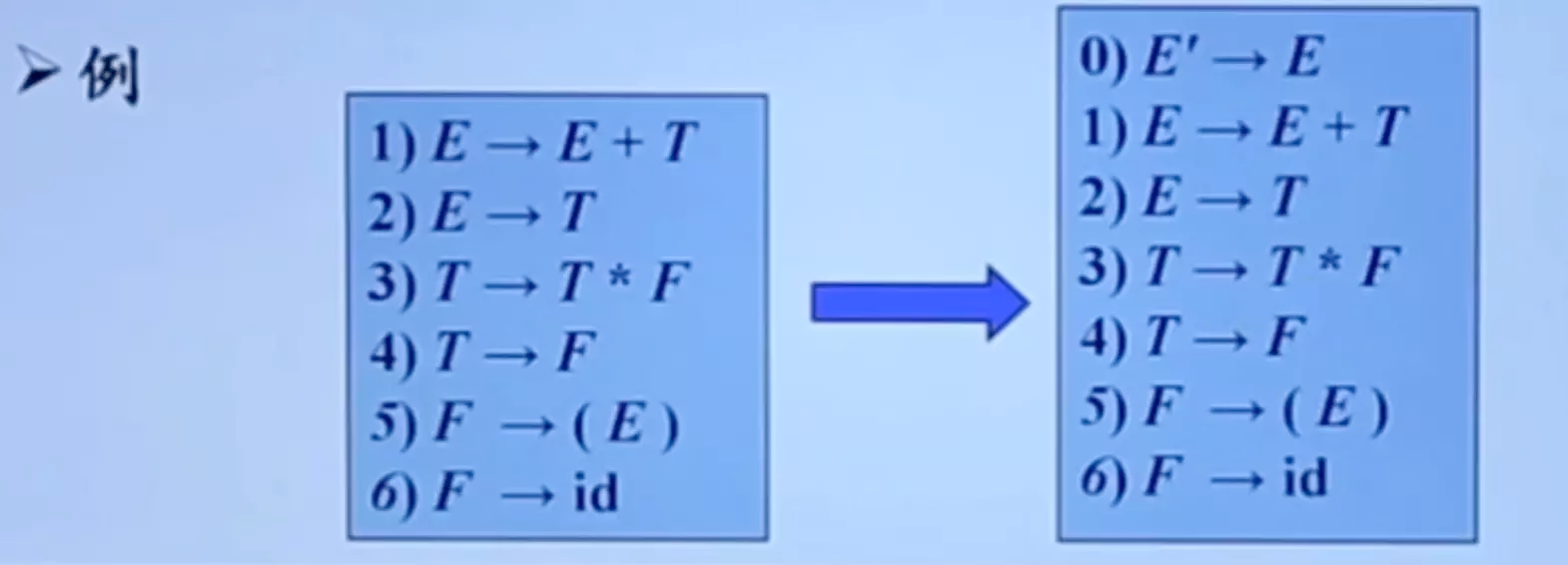
引入这个新的开始产生式的目的是使得 文法开始符号仅出现在一个产生式的左边,从而使得分析器只有一个接受状态
文法中的项目
可以把所有等价的项目组成一个项目集 (I) ,称为 项目集闭包 (Closure of Item Sets) ,每个项目集闭包对应着自动机的一个 状态
后继项目 (Successive Item)
- 同属于一个产生式的项目,但圆点的位置只相差一个符号,则称后者是前者的后继项目
- $A \rightarrow \alpha ·X \beta$ 的后继项目是 $A \rightarrow \alpha X·\beta$
LR(0) 自动机
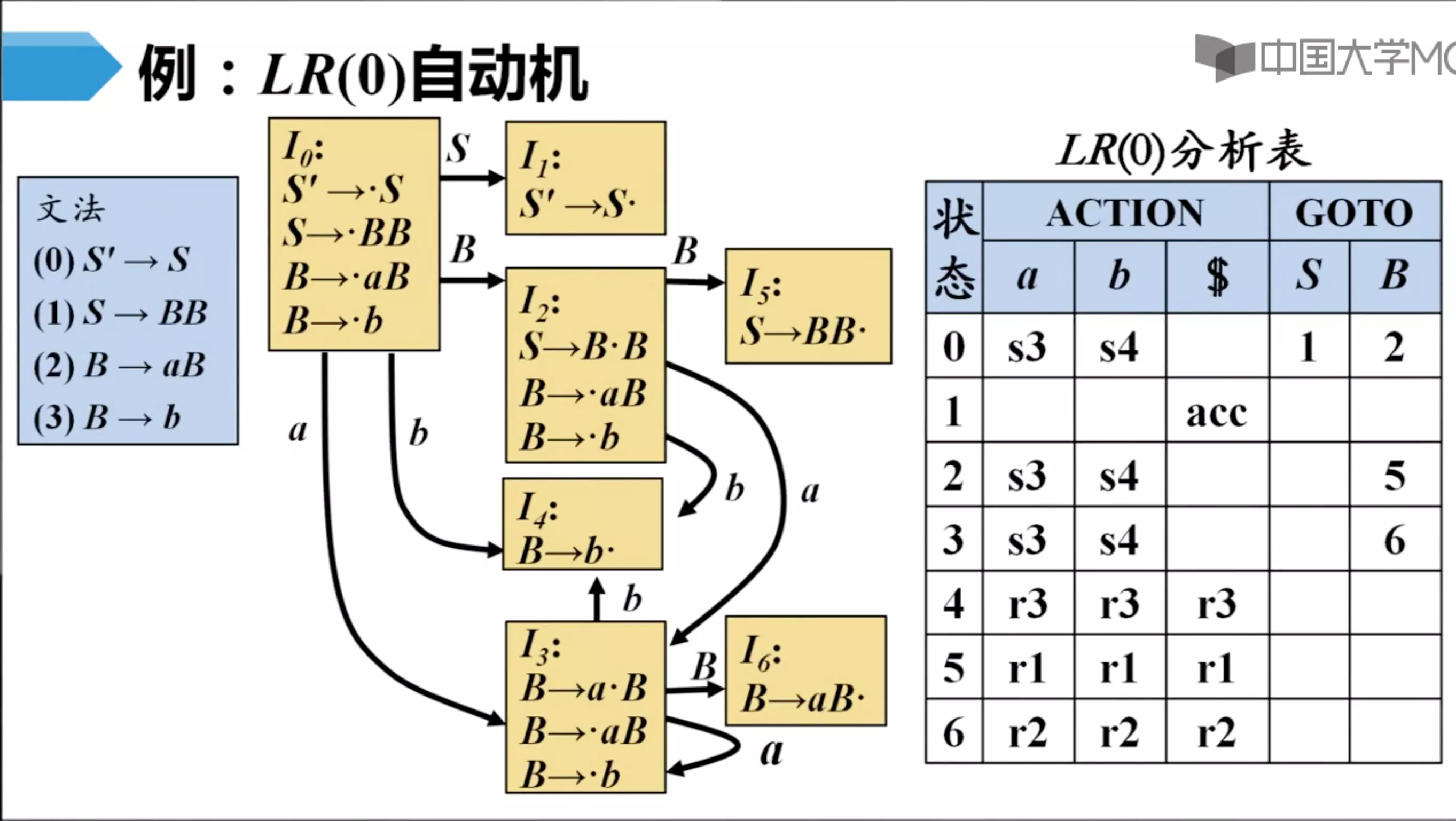
- 如果 LR(0) 分析表中没有语法分析动作冲突,那么给定的文法就称为 LR(0) 文法
- 不是所有的 CFG 都能用 LR(0) 方法进行分析,也就是说,CFG 不总是 LR(0) 文法
LR(1) 分析
LR(1) 分析法的提出
SLR 只是简单地考察 下一个输入符号 b 是否属于与 归约项目 $A \rightarrow \alpha$ 相关联的 FOLLOW(A) ,但 $b \in FOLLOW(A)$ 只是归约 $\alpha$ 的一个必要条件,而非充分条件
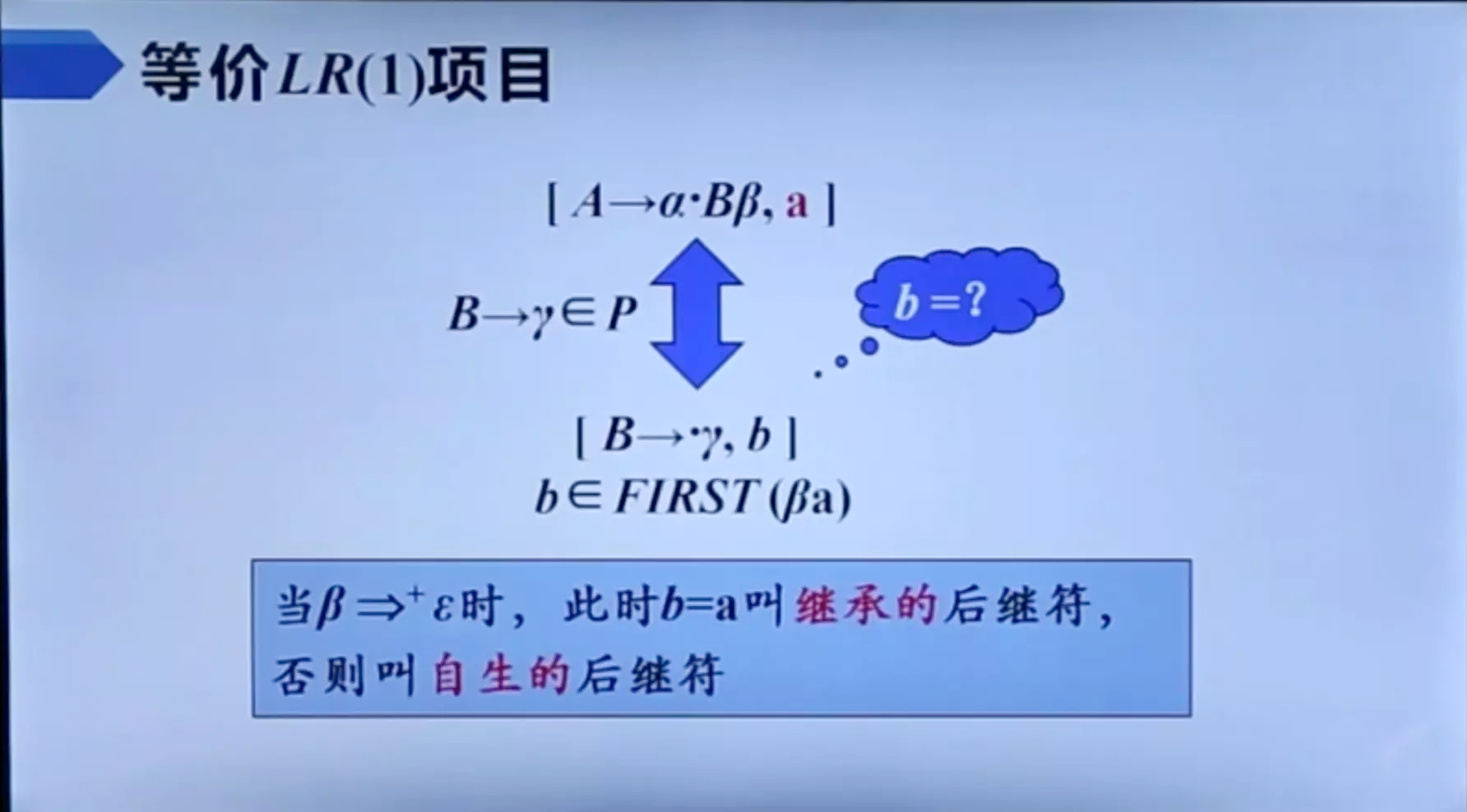
规范 LR(1) 项目
将一般形式为 $[A \rightarrow \alpha · \beta, a]$ 的项称为 LR(1) 项,其中 $A \rightarrow \alpha \beta$ 是一个产生式,a 是一个终结符(这里将 $ 视为一个特殊的终结符)它表示当前状态下,A 后面必须紧跟终结符,称为该项的 展望符 (lookahead)
- LR (1) 中的 1 指的是项的第二个分量的长度
- 在形如 $[A \rightarrow \alpha · \beta, a]$ 且 $\beta \neq \varepsilon$ 的项中,展望符 a 没有任何作用
- 但是一个形如 $[A \rightarrow \alpha ·, a]$ 的项在只有在下一个输入符号等于 a 时才可以按照 $A \rightarrow \alpha$ 进行归约
- 这样的 a 的集合总是 FOLLOW(A) 的子集,而且它通常是一个真子集
等价 LR(1) 项目
LR(1) 自动机
建议去看一遍原视频上的推导过程。
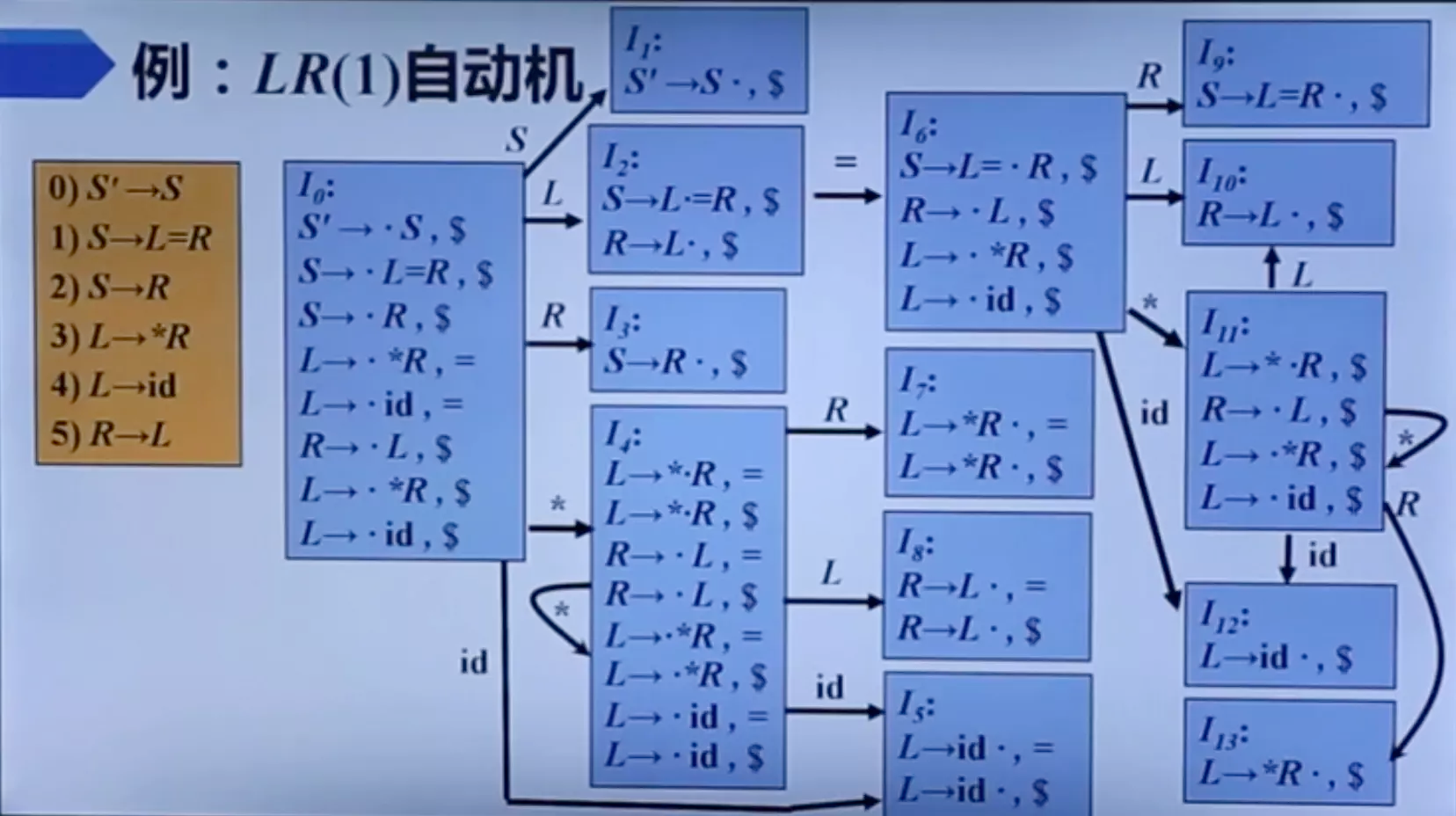
如果除展望符外,两个 LR(1) 项目集是相同的,则称这两个 LR(1) 项目集是 同心 的
LALR 分析法
LALR (lookahead-LR) 分析的基本思想
- 寻找具有相同核心的 LR(1) 项集,并将这些项集合并为一个项集。所谓项集的核心就是其第一份量的集合
- 然后根据合并后得到的项集族构造语法分析表
- 如果分析表中没有语法分析动作冲突,给定的文法就称为 LALR(1) 文法,就可以根据该分析表进行语法分析
LALR 自动机
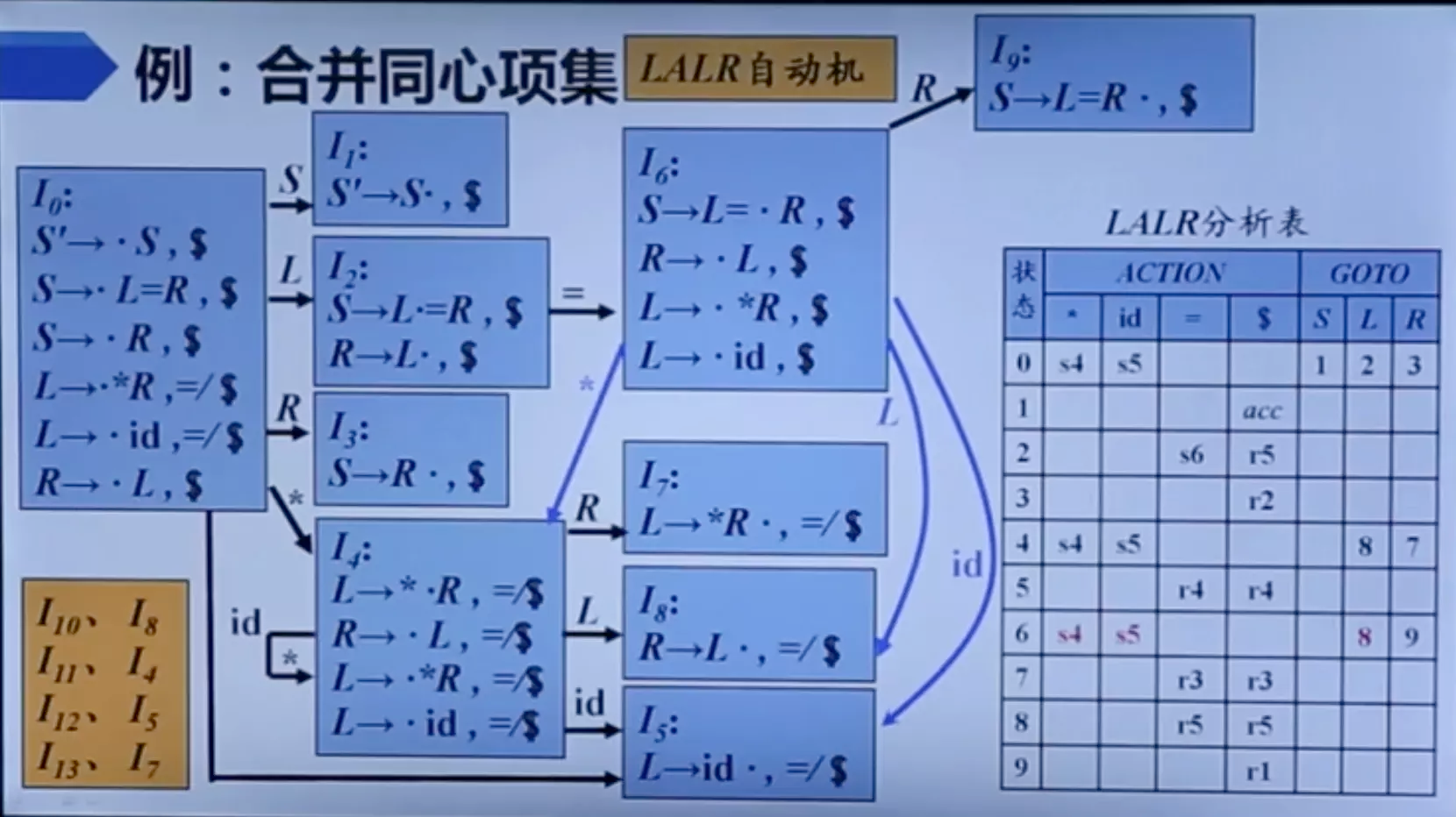
- 合并同心项集不会产生移进-归约冲突
- 合并同心项集后,虽然不产生冲突,但可能会推迟错误的发现
- LALR 分析法可能会作多余的归约动作,但绝不会作错误的移进操作
LALR(1) 的特点
- 形式上与 LR(1) 相同
- 大小上与 LR(0) / SLR 相当
- 分析能力介于 SLR 和 LR(1) 二者之间
$SLR < LALR(1) < LR(1)$ - 合并后的展望符集合仍为 FOLLOW 集的子集
参考
- 哈工大编译原理课程