Queuing Theory 学习笔记
排队理论不是专门为软件系统开发的,而是一种通用的理论,用于计算和优化任何系统的效率,通过消耗多种资源来实现其目标。
排队理论用量化的性能规律统一了所有性能和可扩展性的方面和指标。
为了有效地应对软件性能和可扩展性的挑战,对排队理论有最起码的了解是必要的。
一个典型问题
定义:
- 平均到达率(average arrival rate)- $\lambda$
- 服务率(service rate)- $\mu$
- 系统负荷强度(System load intensity)- $\rho$
求稳定状态条件下需要的并行服务器数量 $m$ ?
$$\rho = \dfrac{ \lambda }{ m \mu }$$
$\rho$ 必须小于 1,所以 $m > \dfrac{ \lambda }{ \mu }$ 。
数学表达式
Processes relevant to queuing theory
- Markov(M) process - memoryless: 过程的未来状态与历史无关,完全取决于现在的状态。
- 到达数量遵循泊松分布(离散值)。
- 抵达时间遵循指数分布(连续值)。
- 服务时间遵循指数分布。
- General(G) process: 不具有任何单一概率分布的特点。
- Deterministic(D) process: 以各种常数为特征。
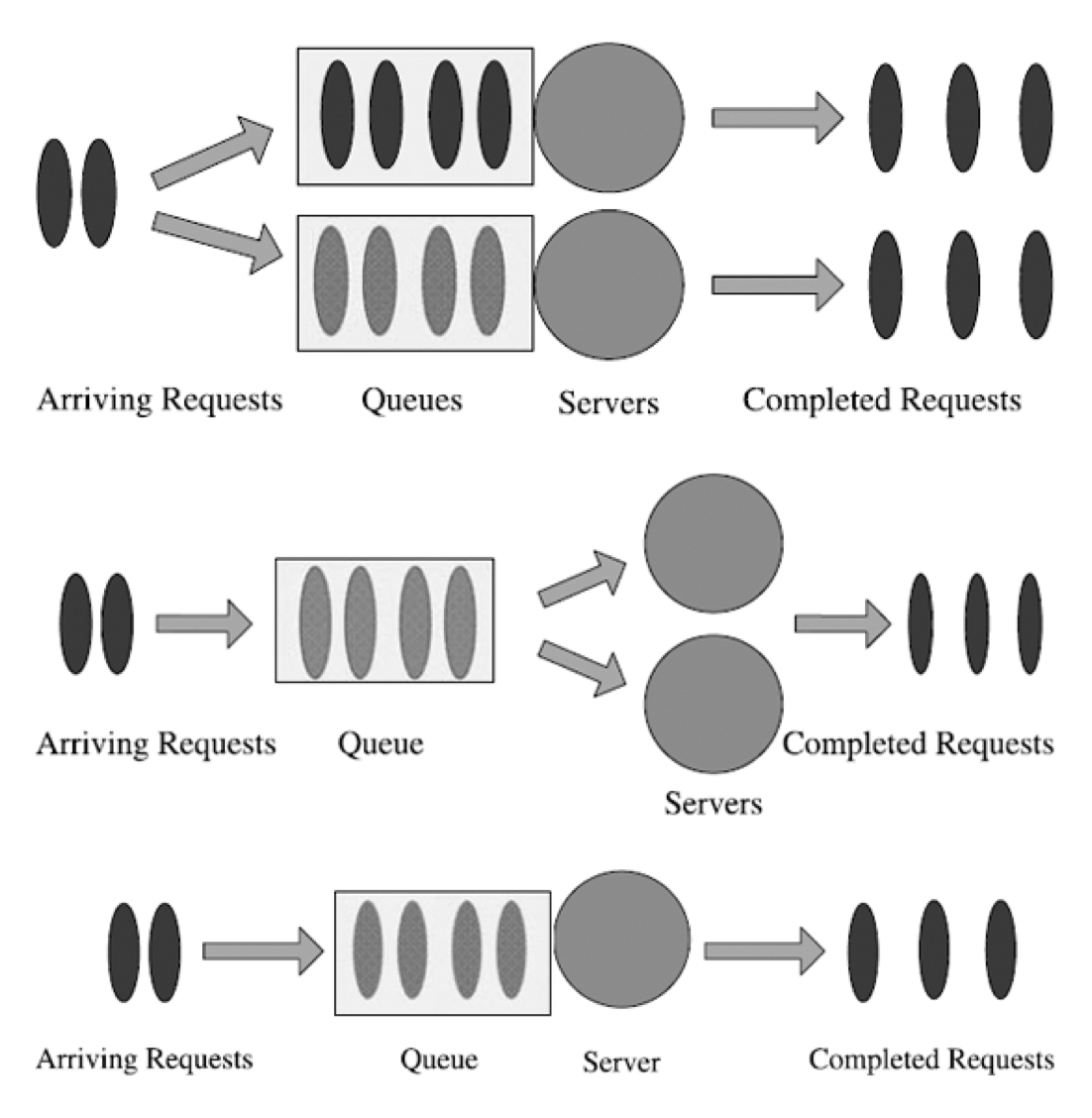
排队节点和排队系统的记法
- 排队节点用下标小写字母 i 表示
- 排队系统的下标符号为零(0)
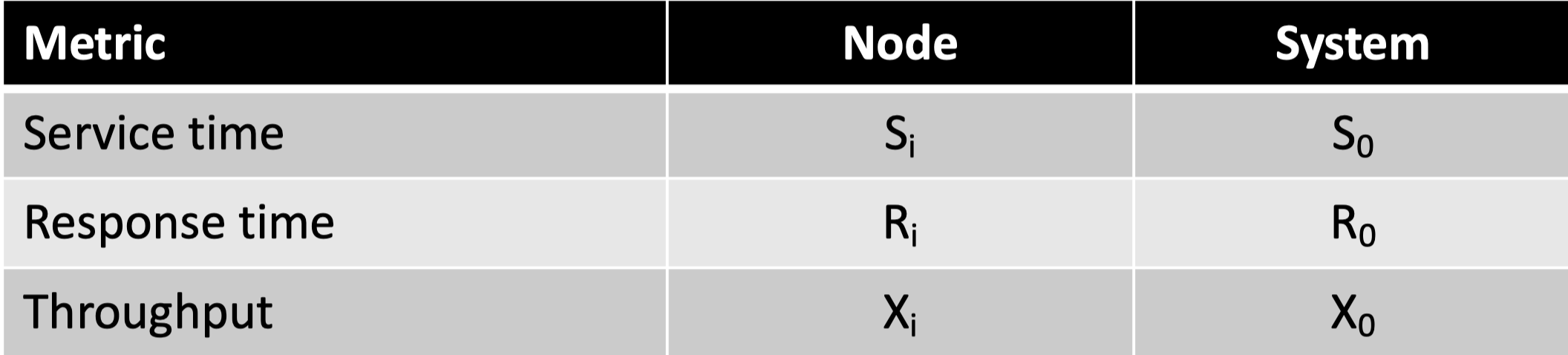
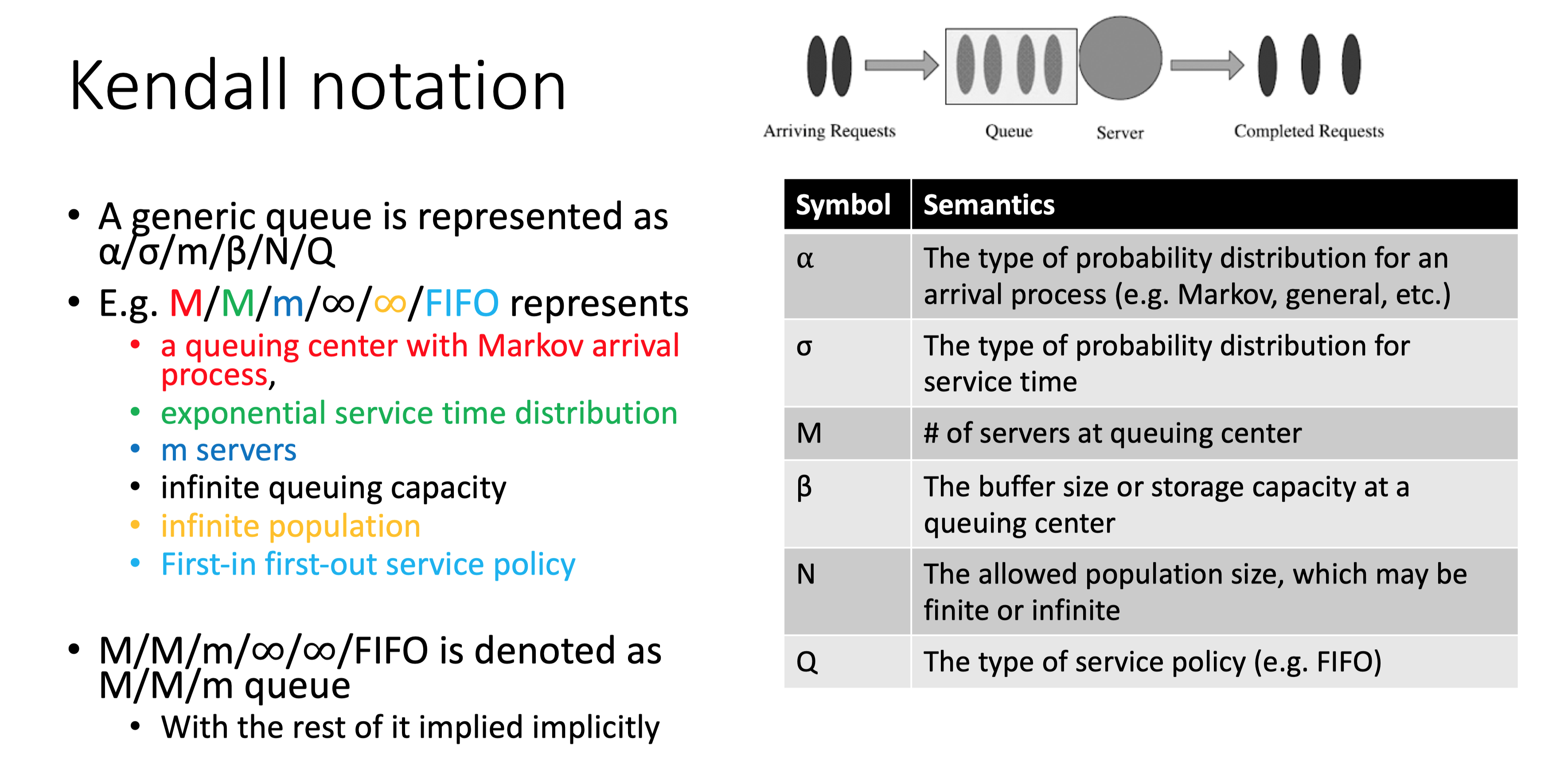
肯德尔记数法(Kendall notation)
网络排队系统的排队模型
- 开放式排队系统(OLTP workloads)
外部输入 + 外部最终目的地。M/M/1- 假设客户进入和退出系统。 - 封闭式排队系统(batch jobs / OLTP workloads)
完全封闭;客户不断循环;从不离开系统。M/M/m/N/N- 假设系统中的客户数量有限。
Little’s law I
吞吐量、响应时间和排队长度 —— 完全量化排队系统的性能。
$$N_{i} = X_{i} \times R_{i}$$
- $N_{i}$ - 等待或接受服务的客户数量
- $X_{i}$ - 吞吐量
- $R_{i}$ - 相应时间
$$R = W + S$$
- $S$ - 服务时间
- $W$ - 等待时间
因此可推出:
- 等待的客户:$N_{i-waiting} = X_{i} W_{i}$
- 正在接受服务的客户:$N_{i-served} = X_{i} S_{i}$
- 总的客户等待数量:$N_{i} = X_{i} W_{i} + X_{i} S_{i}$
M/M/1 开放模型
- 可以使用简单的公式来计算性能指标。
- 用于平衡条件下运行系统的性能预测。
猜想
平均到达率 $\lambda$ 已知
平均吞吐量 = 平均到达率($X_{0} = \lambda$)
已知系统对有关资源的服务需求(service demand) $D_{i}$。
$D_{i} = V_{i} \times S_{i}$
$V_{i}$ - 排队节点的访问次数
$S_{i}$ - 每次平均服务时间
对于服务时间(service time)的解释
- 服务时间 $S_{i}$ 通常用响应时间 $R_{i}$ 来近似表示
- 在排队节点没有反馈的情况下,服务需求和服务时间是一样的,即 $D_{i} = S_{i}$
计算
已知吞吐量 $X_{0}$ 和 第 i 个节点的服务需求 $D_{i}$,那么利用率为
$$U_{i} = X_{0} \times D_{i}$$已知服务需求 $D_{i}$ 和利用率 $U_{i}$ ,那么一个请求在队列节点 i 的平均停留时间是
$$R_{i}^{‘} = \dfrac{ D_{i} }{ 1 - U_{i}} = V_{i} \times R_{i}$$
$V_{i}$ - 是排队节点的访问量总的平均相应时间
$$R_{0}=\sum_{i=1}^{k}R_{i}^{‘}$$已知利用率 $U_{i}$
- $N_{i} = X_{i} \times R_{i}$
- $R_{i} = \dfrac{ S_{i} }{ 1 - U_{i} } = W_{i} + S_{i}$
- $U_{i} = X_{0} \times D_{i}$
计算排队节点 i 的平均客户数
- $N_{i} = \dfrac {U_{i}} {1 - U_{i} }$
- $U_{i} = \dfrac{ N_{i} }{ N_{i} + 1 }$
排队系统中的顾客总人数
$$N = \sum_{i} N_{i}$$
提醒
- OLTP 系统的吞吐量与平衡条件下的到达率相同。
- 批量作业的吞吐量可以用 M/M/m/N/N 封闭模型来计算。
总结
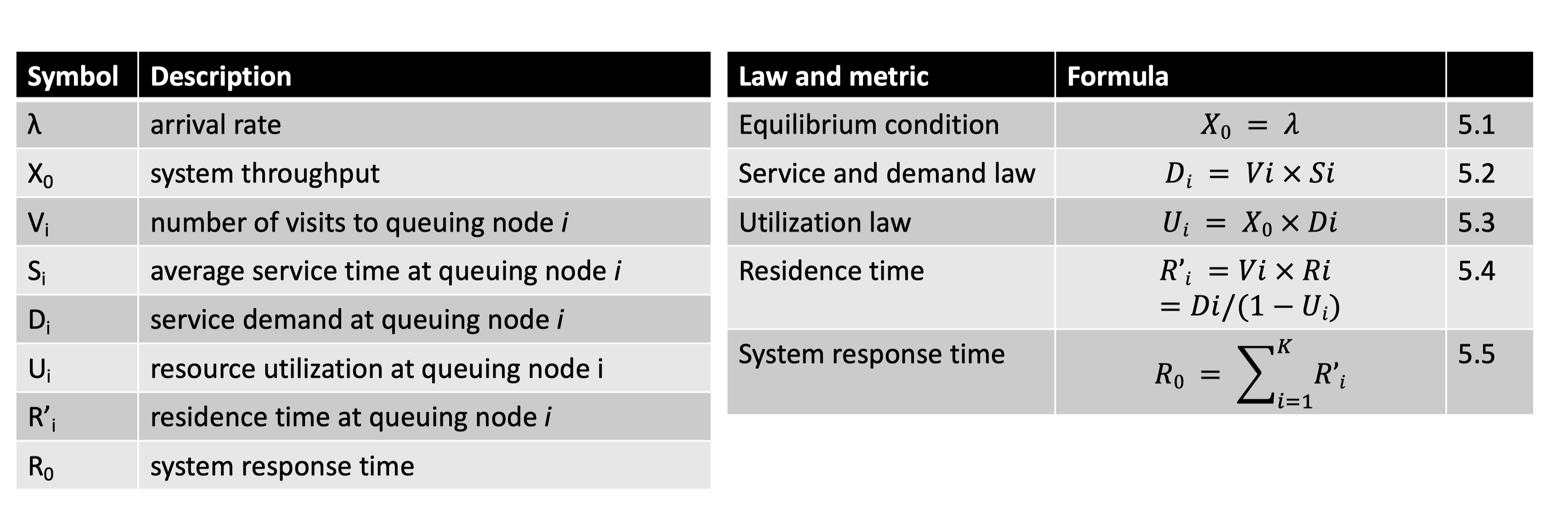
通过 M/M/1 模型,我们可以计算出无反馈的 OLTP 软件系统的响应时间 $R_{0}$ 。
Queuing Systems: 有反馈 VS 无反馈

Little’s law II
利用率,服务时间和响应时间
重写时不考虑是针对排队节点还是排队系统,省略 i
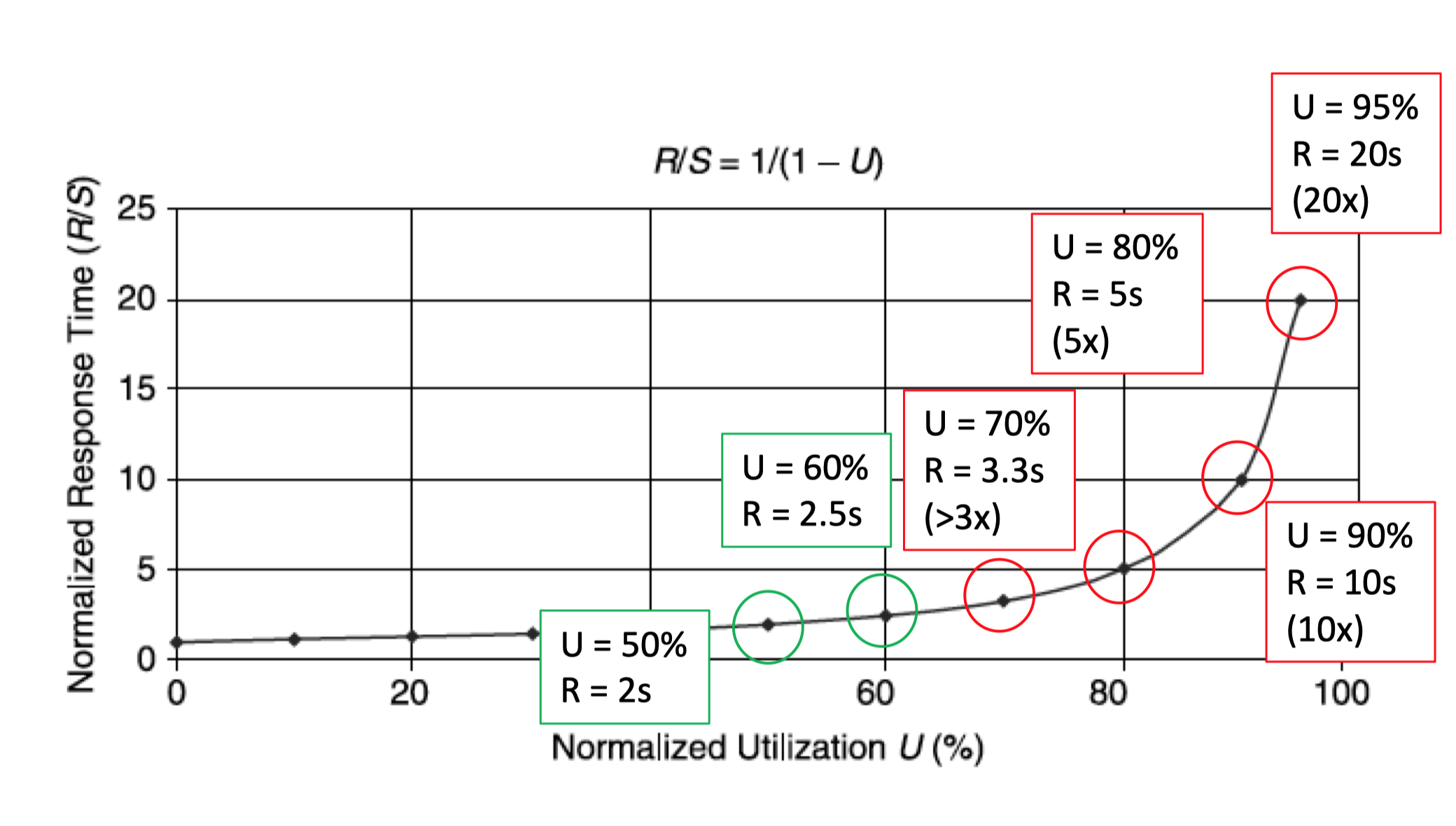
$$R = \dfrac{ S }{ 1 - U }$$
响应时间 VS 资源利用率
- 利用率增加 = 相应时间增加
- OLTP 系统的利用率应保持在70%以下。
- 响应时间的增加不应超过服务时间的 3 倍。
M/M/m/N/N 模型(封闭的)

M/M/1/N/N in Java
1 | // a java program for solving M/M/1/N/N |
例题
一个 OLTP 工作负载由部署在单一 Web 服务器上的 Web 应用程序的单一类型的用户活动组成,该应用程序服务于静态 HTML 内容。据统计,该应用在 Web 服务器上处理一个用户事务平均需要 200ms 的服务时间。该 Web 服务器是由多个应用共享的。
计算上述用户场景下,当 Web 服务器利用率为 50% 时的平均响应时间?
$S = 200ms = 0.2s$
$U = 50% = 0.5$
$R = \frac{S}{1 - U} = \frac{0.2}{1 - 0.5} = \frac{0.2}{0.5}=0.4$
如果该 Web 服务器利用率接近 100% ,你需要作出以下选择:
- 增加一个相同的系统,或着
- 将同一台服务器的 CPU 容量增加一倍,要么:
- 通过增加两倍数量的相同处理器,或着
- 通过用速度快 2 倍的处理器替换现有的处理器。
选择并说明理由。
$S = 0.2$
$U = 1$
Scale out
$U^{new} = \frac{U}{n} = \frac{U}{2} = 0.5 $
$R = \frac{S}{1 - U^{new}} = 0.4$
Scale up by adding a processor
$U^{new} = \frac{U}{2} = 0.5$
$R = \frac{S}{1-U^{2}} = \frac{0.2}{1 - 0.25} = 0.27$
Scale up by using a double speed processor
$U = X \times D \approx X \times S$
$U^{new} = X \times S^{new} = \frac{X \times S}{2} = \frac{U}{2}$
$S^{new} = 0.1$
$U^{new} = \frac{U}{2} = 0.5$
$R = \frac{S^{new}}{1 - U^{new}} = \frac{0.1}{1 - 0.5} = 0.2$
结论:Scaling-up 比使用 Scaling-out 方法获得的性能提高 65% 或 100%。
![3choice]()