[译] Unsloth - LoRA 超参数指南
LoRA 超参数是可调节的参数,用于控制低秩适应(LoRA)对大型语言模型(LLMs)进行微调的方式。由于存在诸多选项(如学习率和训练轮次等)以及数百万种可能的组合,因此选择合适的参数值至关重要,这有助于在微调过程中实现更高的准确性、稳定性和质量,并减少幻觉现象的出现。
你将基于数百篇研究论文和实验的洞见,学习这些参数的最佳实践,并了解它们如何对模型产生影响。尽管我们建议使用 Unsloth 的默认设置,但理解这些概念将使你能够完全掌控微调过程。
目标是通过调整超参数数值来提升准确性,同时抑制过拟合或欠拟合问题。过拟合是指模型过度记忆训练数据,从而削弱其对未见过的新输入的泛化能力。我们的目标是让模型具备良好的泛化能力,而非仅仅机械记忆数据。
关键微调超参数
学习率(Learning Rate)
定义了在每个训练步骤中模型权重的调整幅度。
- 更高的学习率:会使初始收敛速度更快,但如果设置得过高,可能导致训练变得不稳定,或无法找到最优的最小值。
- 更低的学习率:会使训练过程更加稳定和精确,但可能需要更多的训练轮次才能收敛,从而增加整体训练时间。尽管人们通常认为低学习率会导致欠拟合,但实际上它也可能导致过拟合,甚至会阻碍模型的学习能力。
- 典型范围:
2e-4(0.0002)至5e-6(0.000005)。- 对于常规的 LoRA/QLoRA 微调,我们建议将
2e-4作为起始学习率。 - 对于强化学习(如 DPO、GRPO 等),我们建议使用
5e-6的学习率。 - 对于全量微调,通常较低的学习率更为合适。
- 对于常规的 LoRA/QLoRA 微调,我们建议将
轮次(Epochs)
模型完整遍历训练数据集的次数。
- 更多的训练轮次:有助于模型更好地学习,但轮次过多会导致模型记住训练数据,损害其在新任务上的表现。
- 更少的训练轮次:可缩短训练时间并防止过拟合,但如果轮次不足,模型可能无法学习到数据集的潜在模式,从而导致训练不充分。
- 建议:1-3 轮次。对于大多数基于指令的数据集,训练超过 3 轮次的收益会逐渐递减,并会增加过拟合的风险。
LoRA 或 QLoRA
LoRA 使用 16 位精度,而 QLoRA 是一种 4 位微调方法。
- LoRA:16 位微调方法。其速度略快且精度略高,但显存消耗显著更多(是 QLoRA 的 4 倍)。建议在 16 位环境以及需要最高精度的场景中使用。
- QLoRA:4 位微调方法。速度略慢且精度稍低,但显存占用量大幅减少(仅为前者的 1/4)。
- 使用 Unsloth 中的 QLoRA 技术,700 亿参数的 LLaMA 模型可在小于 48GB 的显存中运行。更多细节在这里
超参数和建议
| 超参数 | 功能 | 推荐设置 |
|---|---|---|
LoRA Rank (r) |
控制 LoRA 适配器矩阵中可训练参数的数量。秩越高,模型容量越大,但内存占用也会增加。 | 8, 16, 32, 64, 128 选择 16 或 32。 |
| LoRA Alpha ( lora_alpha) |
缩放与秩(r)相关的微调调整强度。 |
r (标准)或 r * 2 (常见启发式方法) |
| LoRA Dropout | 一种正则化技术,在训练过程中随机将一部分 LoRA 激活值设为零,以防止过拟合。该技术作用有限,因此我们默认将其设为 0。 | 0 (默认)到 0.1 |
| Weight Decay | 一种正则化项,通过惩罚较大的权重来防止过拟合并提高泛化能力。注意不要设置过大的数值! | 0.01 (推荐)到 0.1 |
| Warmup Steps | 在训练开始时逐步提高学习率。 | 总步数的 5-10% |
| Scheduler Type | 在训练过程中动态调整学习率。 | linear 或 cosine |
Seed (random_state) |
为确保结果的可重复性而设置的固定数值。 | 任意整数(例如,42、3407) |
| Target Modules | 你希望将 LoRA 适配器应用于模型的哪个部分 - 注意力层或多层感知机,或两者皆可。 注意力层: q_proj, k_proj, v_proj, o_proj MLP: gate_proj, up_proj, down_proj |
建议所有的线性层:q_proj, k_proj, v_proj, o_proj, gate_proj, up_proj, down_proj |
梯度累积步数与批量大小的等效性
有效批量大小
正确配置批量大小对于在训练稳定性和 GPU 显存限制之间取得平衡至关重要。这由两个参数控制,它们的乘积即为有效批量大小。
有效批量大小 = batch_size * gradient_accumulation_steps
- 更大的有效批量大小通常会使训练过程更平滑、更稳定。
- 较小的有效批量大小可能会引入更多的随机性。
尽管每个任务各不相同,但以下配置为实现稳定的 16 有效批量大小提供了一个很好的起点,该配置适用于现代 GPU 上的大多数微调任务。
| 参数 | 描述 | 推荐设置 |
|---|---|---|
批量大小(batch_size) |
在单个 GPU 上单次前向/反向传播过程中处理的样本数量。 显存占用的主要因素。更高的值可以提高硬件利用率并加快训练速度,但前提是它们能在显存中放得下。 |
2 |
| 梯度累积 ( gradient_accumulation_steps) |
执行单次模型权重更新前需要处理的小批量数量。 训练时间的主要决定因素。通过模拟更大的批量大小来节省显存。数值越高,每个训练轮次的时间越长。 |
8 |
| 有效批量大小(计算得出) | 每次梯度更新所使用的真实批量大小。它直接影响训练的稳定性、质量以及最终的模型性能。 | 4 到 16 推荐:16(2*8) |
显存与性能的权衡
假设你希望每个训练步骤处理 32 个数据样本,那么你可以执行以下操作:
batch_size = 32, gradient_accumulation_steps = 1batch_size = 16, gradient_accumulation_steps = 2batch_size = 8, gradient_accumulation_steps = 4batch_size = 4, gradient_accumulation_steps = 8batch_size = 2, gradient_accumulation_steps = 16batch_size = 1, gradient_accumulation_steps = 32
尽管所有这些配置在模型权重更新方面是等效的,但它们对硬件的要求却大相径庭。
第一种配置(batch_size = 32)会消耗最多的显存,且在大多数 GPU 上可能无法运行。最后一种配置(batch_size = 1)显存消耗最少,但代价是训练速度会略微变慢。为避免出现 OOM(内存不足)错误,建议始终设置较小的 batch_size,并通过增加 gradient_accumulation_steps 来达到你目标的有效批量大小。
Unsloth 梯度累积修复
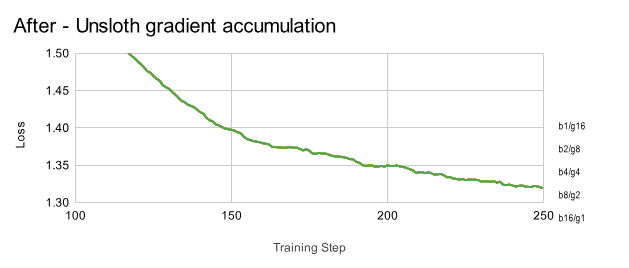
由于我们对梯度累积的错误修复,在 Unsloth 中梯度累积和批量大小现已完全等效。我们针对梯度累积实施了特定的错误修复,解决了一个常见问题,即这两种方法此前无法产生相同的结果。这曾是业界广泛面临的挑战,但对于 Unsloth 用户而言,现在这两种方法可互换使用。
欲了解更多详情,请阅读我们的博客文章。
在我们进行修复之前,即使 batch_size 和 gradient_accumulation_steps 的组合得到相同的有效批量大小(即 batch_size × gradient_accumulation_steps = 16),训练表现也并不等效。例如,像 b1/g16、b2/g8、b4/g4、b8/g2 和 b16/g1 这样的配置,有效批量大小均为 16,但如图表所示,使用标准梯度累积时,损失曲线并不一致:
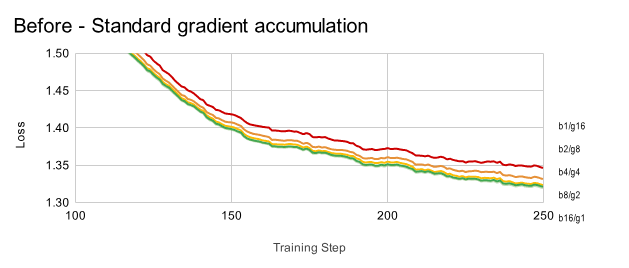
应用我们的修复后,无论以何种方式实现 16 的有效批量大小,损失曲线现在都能正确对齐:
Unsloth 中的 LoRA 超参数
以下展示了一个标准配置。尽管 Unsloth 提供了优化的默认设置,但理解这些参数是手动调优的关键。
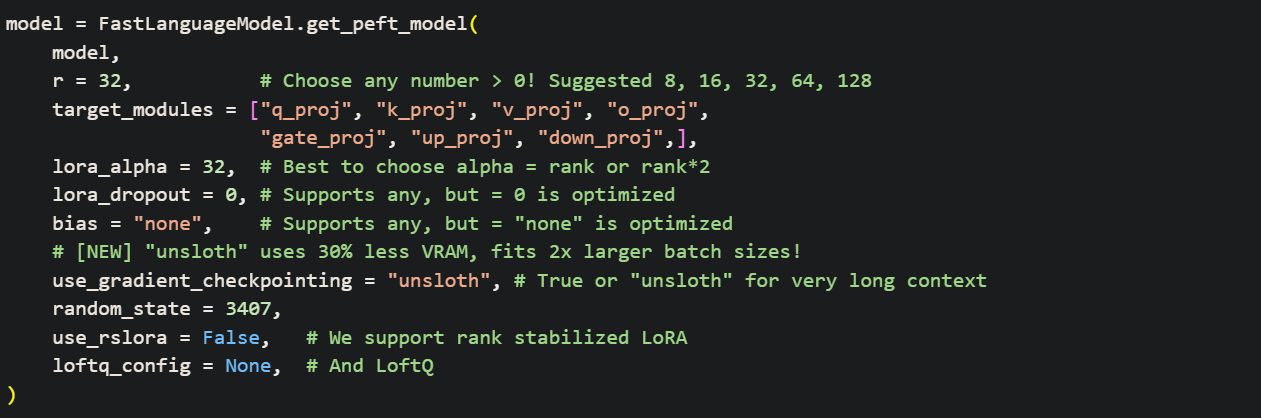
r = 16, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128:微调过程的秩(r)。较大的秩会占用更多内存且运行更慢,但可提高复杂任务的准确性。我们建议秩取值如 8 或 16(用于快速微调),最大可达 128。秩设置过大可能导致过拟合,损害模型质量。target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj",],:为了获得最佳性能,应将 LoRA 应用于所有线性层。研究表明,针对所有层进行优化对于匹配全量微调的性能至关重要。尽管可以通过移除模块来减少内存占用,但我们强烈建议不要这样做,以确保模型质量最大化。lora_alpha = 16,:一个控制微调调整强度的缩放因子。将其设置为与秩(r)相等是一个可靠的基准。一种流行且有效的启发式方法是将其设置为秩的两倍(r * 2),这通过给 LoRA 更新赋予更多权重,使模型学习得更积极。lora_dropout = 0, # Supports any, but = 0 is optimized:一种正则化技术,通过在每个训练步骤中随机将一部分 LoRA 激活值设为零来帮助防止过拟合。近期研究表明,对于微调中常见的短训练周期,lora_dropout可能是一种不可靠的正则化方法。当lora_dropout = 0时,Unsloth 的内部代码可优化训练过程,使其速度略有提升。但如果您怀疑模型存在过拟合问题,我们建议设置非零值。bias = "none", # Supports any, but = "none" is optimized:为加快训练速度并减少内存占用,请将此设置保留为“none”。该设置会避免训练线性层中的偏置项,因为这些偏置项虽会增加可训练参数,但几乎不会带来实际收益。use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context:选项包括True、False和"unsloth"。我们推荐使用"unsloth",因为它能额外减少 30% 的内存占用,并支持极长上下文的微调。您可以在我们关于长上下文训练的博客文章中了解更多信息。random_state = 3407,:用于确保运行具有确定性和可重复性的随机种子。由于训练过程涉及随机数,因此设置固定的种子对于保证实验结果的一致性至关重要。use_rslora = False, # We support rank stabilized LoRA:一项实现了 Rank-Stabilized LoRA 的高级功能。如果设置为True,有效缩放将变为 $\frac{\text{lora_alpha}}{\sqrt{r}}$,而非标准的 $\frac{\text{lora_alpha}}{r}$。这有时能提高稳定性,尤其是在较高秩的情况下。loftq_config = None, # And LoftQ:这是一种 LoftQ 所提出的高级技术,它利用预训练权重中的前 ‘r’ 个奇异向量来初始化 LoRA 矩阵。这一方法能够提升模型精度,但在训练开始时可能会导致显著的内存激增。
LoRA Target Modules 和 QLoRA vs LoRA
使用 target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj",] 来同时针对 MLP 和注意力层,以提高准确性。
QLoRA 采用 4 位精度,可将显存占用减少 75% 以上。
LoRA(16位)精度略高,速度也更快。
根据实证实验和原始 QLoRA 论文等研究文献,将 LoRA 同时应用于注意力层和 MLP 层效果最佳。
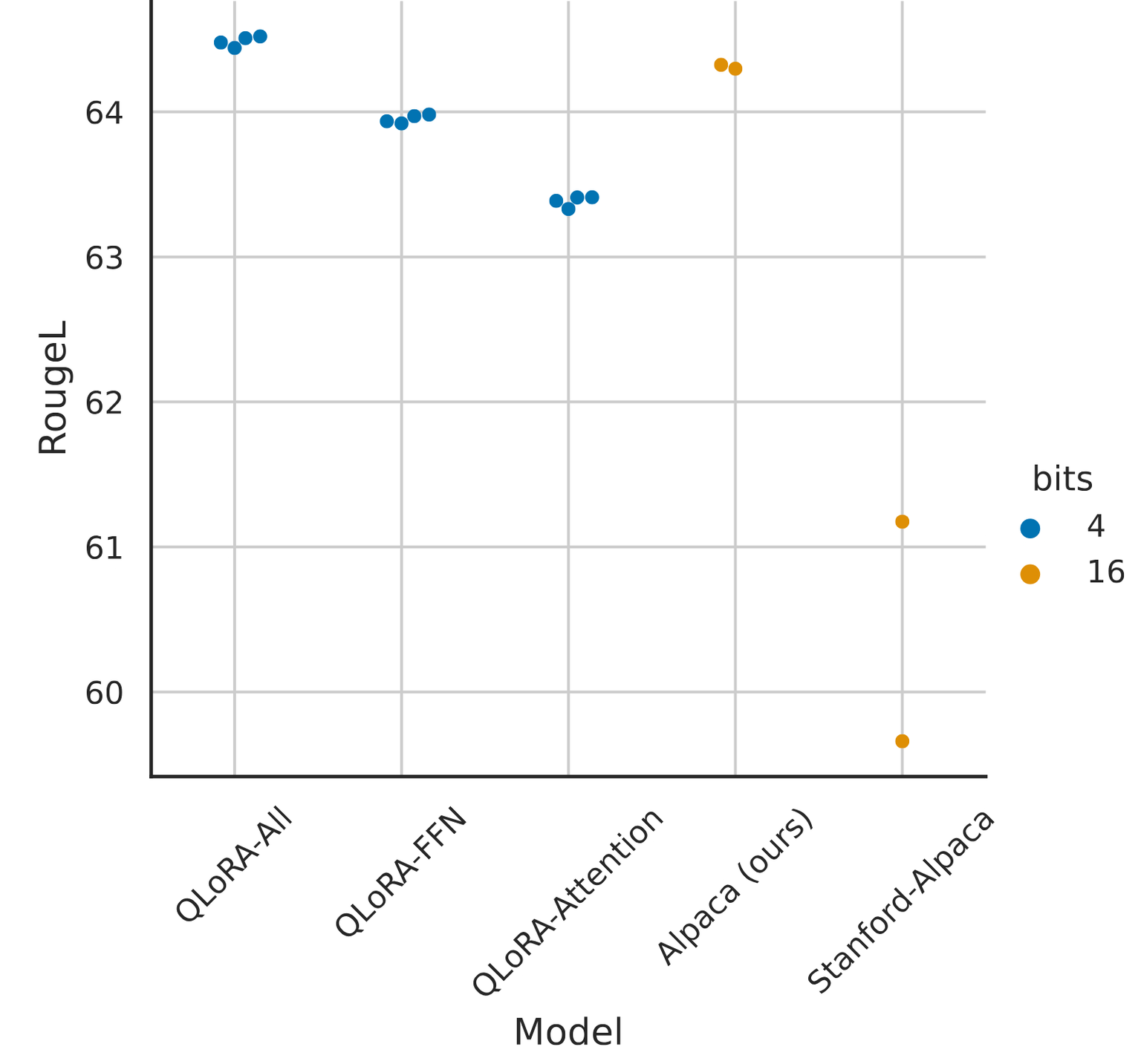
上图展示了不同目标模块的 RougeL 分数(分数越高越好),以及 LoRA 与 QLoRA 的对比情况。
前 3 个点展示了:
- QLoRA-All:在所有前馈神经网络(FFN)/多层感知机(MLP)和注意力层上应用 LoRA。这是最佳方案!
- QLoRA-FFN:仅在 FFN(前馈神经网络)上应用 LoRA。相当于针对
gate_proj、up_proj、down_proj这些模块。 - QLoRA-attention:仅在注意力层上应用 LoRA。相当于针对
q_proj、k_proj、v_proj、o_proj这些模块。
仅针对补全内容进行训练,将输入内容屏蔽
QLoRA 论文表明,屏蔽补全,输出,或 assistant 消息可进一步将准确率提升几个百分点(1%)。以下展示了 Unsloth 内部的实现示例。

QLoRA 论文指出,仅针对补全内容进行训练能显著提升模型准确率,尤其是在多轮对话式微调任务中!我们在对话相关的 notebook 中采用了此方法。

在 Unsloth 中启用针对补全内容的训练时,需要自行确定 instruction 和 assistant 部分。我们计划在未来实现这一过程的自动化!
对于 Llama 3、3.1、3.2、3.3 和 4 模型,你可以按如下方式定义这些部分:
1 | from unsloth.chat_templates import train_on_responses_only |
对于 Gemma 2、3、3n 模型,你可以按如下方式定义这些部分:
1 | from unsloth.chat_templates import train_on_responses_only |
避免过拟合和欠拟合
过拟合(泛化能力差/过度专门化)
模型记住了训练数据(包括其中的统计噪声),因此无法对未见过的数据进行泛化。
如果训练损失降至 0.2 以下,模型很可能已过拟合 - 此时模型在未见过的任务上表现往往不佳。
一个简单技巧是 LoRA alpha 缩放:直接将每个 LoRA 矩阵的 alpha 值乘以 50%,这会减弱微调的影响。
这与权重合并/平均相关。
你可以获取原始基础(或指令)模型,添加 LoRA 权重,然后将结果除以 2。这将得到一个平均模型 — 其功能等效于将 alpha 值减半。
解决方案:
- 调整学习率:较高的学习率常导致过拟合,尤其是在短周期训练中。对于长周期训练,较高学习率可能效果更好,建议通过实验对比效果。
- 减少训练轮次(epochs):在 1、2 或 3 轮后停止训练。
- 增加
weight_decay。初始值可设为 0.01 或 0.1。 - 增大
lora_dropout。使用 0.1 等数值增强正则化效果。 - 增大批量大小或梯度累积步数。
- 扩展数据集:将开源数据集与自有数据合并或拼接,优先选择高质量数据。
- 基于评估早停训练:启用评估机制,当评估损失连续几步上升时终止训练。
- LoRA Alpha 缩放:训练后及推理阶段缩小 alpha 值,减弱微调影响。
- 权重平均:将原始指令模型与微调模型的权重相加后除以 2。
欠拟合(过于泛化)
模型无法捕捉训练数据中的潜在模式,通常是由于模型复杂度不足或训练时长不够。
解决方案:
- 调整学习率:若当前学习率过低,提高学习率可能加速收敛(尤其在短周期训练中);长周期训练可尝试降低学习率,通过测试确定最优方案。
- 增加训练轮次(epochs):延长训练周期,但需监控验证损失以避免过拟合。
- 增大 LoRA 秩(
r)和 alpha 值:秩应至少与 alpha 值相等,小模型或复杂数据集需更大的秩(通常在 4 到 64 之间)。 - 使用更贴合领域的数据集:确保训练数据高质量且与目标任务直接相关。
- 将批量大小(batch size)降至 1:这会使模型的更新更加激进。
微调没有单一的“最佳”方法,只有最佳实践。实验是找到适合您特定需求的关键。我们的笔记本基于多篇论文研究和我们的实验自动设置最佳参数,为您提供一个很好的起点。祝微调顺利!
致谢:非常感谢 Eyera 对本指南的贡献!