时间复杂度与空间复杂度 时间频度
一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。并且一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度。记为 $T\left( n\right)$。
时间复杂度
在刚才提到的时间频度中,n 称为问题的规模,当 n 不断变化时,时间频度 $T\left( n\right)$ 也会不断变化。但有时我们想知道它变化时呈现什么规律。为此,我们引入时间复杂度概念。 一般情况下,算法中基本操作重复执行的次数是问题规模 n 的某个函数,用 $T\left( n\right)$ 表示,若有某个辅助函数 $f\left( n\right)$ ,使得当 n 趋近于无穷大时,$\dfrac {T\left( n\right) }{f\left( n\right) }$ 的极限值为不等于零的常数,则称 $f\left( n\right)$ 是 $T\left( n\right)$ 的同数量级函数。记作 $T\left( n\right) =O\left( f\left( n\right) \right)$ ,称 $O\left( f\left( n\right) \right)$ 为算法的渐进时间复杂度,简称时间复杂度。
在各种不同算法中,若算法中语句执行次数为一个常数,则时间复杂度为 $O\left( 1\right)$,另外,在时间频度不相同时,时间复杂度有可能相同,如$T\left( n\right) =n^{2}+3n+4$ 与 $T\left( n\right) =4n^{2}+2n+1$ 它们的频度不同,但时间复杂度相同,都为 $O\left(n^{2}\right)$ 。
常见的算法时间复杂度由小到大依次为:$O\left(1\right) < O\left( \log _{2}n\right) < O\left(n\right) < O\left( n\log _{2}n\right) < O\left(n^{3}\right) < … < O\left( 2^{n}\right) < O\left( n!\right)$
求解算法时间复杂度的具体步骤
找出算法中的基本语句:
计算基本语句的执行次数的数量级:
用大 O 记号表示算法的时间性能:
空间复杂度
类似于时间复杂度的讨论,一个算法的空间复杂度 $S\left( n\right)$ 定义为该算法所耗费的存储空间,它也是问题规模 n 的函数。渐近空间复杂度也常常简称为空间复杂度。
空间复杂度 ( Space Complexity ) 是对一个算法在运行过程中临时占用存储空间大小的量度。一个算法在计算机存储器上所占用的存储空间,包括存储算法本身所占用的存储空间,算法的输入输出数据所占用的存储空间和算法在运行过程中临时占用的存储空间这三个方面。算法的输入输出数据所占用的存储空间是由要解决的问题决定的,是通过参数表由调用函数传递而来的,它不随本算法的不同而改变。存储算法本身所占用的存储空间与算法书写的长短成正比,要压缩这方面的存储空间,就必须编写出较短的算法。算法在运行过程中临时占用的存储空间随算法的不同而异,有的算法只需要占用少量的临时工作单元,而且不随问题规模的大小而改变,我们称这种算法是“就地”进行的,是节省存储的算法,如这一节介绍过的几个算法都是如此;有的算法需要占用的临时工作单元数与解决问题的规模 n 有关,它随着 n 的增大而增大,当 n 较大时,将占用较多的存储单元,例如快速排序和归并排序算法就属于这种情况。
常见的算法时间复杂度和空间复杂度
排序法
最差时间分析
平均时间复杂度
稳定度
空间复杂度
冒泡排序
$O\left( n^{2}\right)$
$O\left( n^{2}\right)$
稳定
$O\left( 1\right)$
快速排序
$O\left( n^{2}\right)$
$O\left( n\log _{2}n\right)$
不稳定
$O\left( \log _{2}n\right) \sim O\left( n\right)$
选择排序
$O\left( n^{2}\right)$
$O\left( n^{2}\right)$
稳定
$O\left( 1\right)$
二叉树排序
$O\left( n^{2}\right)$
$O\left( n\log _{2}n\right)$
不一定
$O\left( n\right)$
插入排序
$O\left( n^{2}\right)$
$O\left( n^{2}\right)$
稳定
$O\left( 1\right)$
堆排序
$O\left( n\log _{2}n\right)$
$O\left( n\log _{2}n\right)$
不稳定
$O\left( 1\right)$
希尔排序
$O\left( n^{2}\right)$
unsure
不稳定
$O\left( 1\right)$
峰值查找 - Find Peak Element 定义
A peak element is an element that is greater than its neighbors.
定义中要求我们在一个无序数组中找到一个 peak 元素。所谓 peak 指该元素比前后两个元素都要大,一个无序数组中可能有多个 peak 元素,返回任意一个即可。
解法一:遍历 遍历数组,返回第一个 peak 元素即可。复杂度为 $O\left( n\right)$ 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class PeakFinder { public int PeakFind (int [] nums) { for (int i = 1 ; i<nums.length-1 ; i++){ if (nums[i] > nums[i-1 ] && nums[i] > nums[i+1 ]){ return i; } } return nums.length <=1 || nums[0 ] > nums[1 ] ? 0 : nums.length-1 ; } public static void main (String[] args) { PeakFinder pf = new PeakFinder (); int nums[] = {1 ,3 ,5 ,2 ,8 }; System.out.println("The first index of peak element is: " +pf.PeakFind(nums)); } }
解法二:二分法 首先找到中间节点 mid ,如果大于两边的元素则返回当前序号即可。如果左边的节点比 mid 大,那么我们可以继续在左半区间查找,因为从 mid 往左半边元素呈现向上增长的趋势,并且要求中已经假设 num [ -1 ] 的值为负无穷大,所以左侧区间必然存在一个 peak 。右半区间同理。时间复杂度为 $O\left( \log n\right)$
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public class PeakFinder { public int PeakFind (int [] nums) { int start = 0 ; int end = nums.length-1 ; int mid = 0 ; while (start <= end){ mid = (start + end) / 2 ; if ( ( mid == 0 || nums[mid] >= nums[mid-1 ]) && (mid == nums.length-1 || nums[mid] >= nums[mid+1 ]) ){ return mid; } else if ( mid > 0 && nums[mid-1 ] > nums[mid]){ end = mid -1 ; } else { start = mid +1 ; } } return mid; } public static void main (String[] args) { PeakFinder pf = new PeakFinder (); int [] nums = {2 ,4 ,3 ,6 ,8 }; System.out.println("The index of peak element is : " +pf.PeakFind(nums)); } }
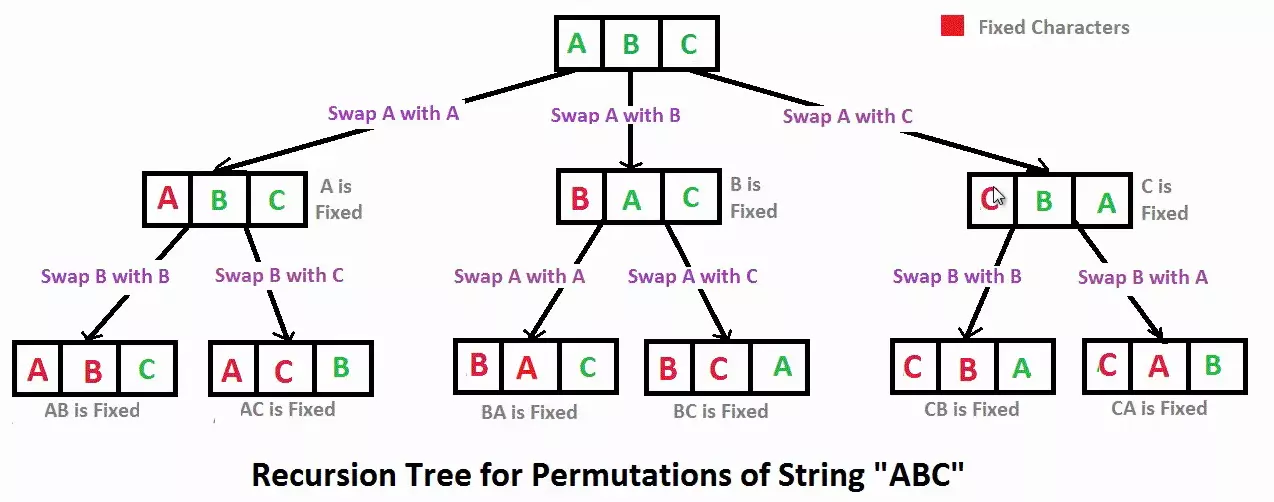
全排列 定义 输入一个字符串,打印该字符串中字符的所有排列。如输入 abc,打印字符 a 、b、c 所能排列出来的所有字符串:abc、acb、bac、bca、cab、cba。
解法一 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class Permutation { public void permutation (String str,String result,int len) { if (result.length()==len){ System.out.println(result); } else { for (int i=0 ;i<str.length();i++){ if (result.indexOf(str.charAt(i))<0 ){ permutation(str, result+str.charAt(i), len); } } } } public static void main (String args[]) throws Exception { String s = "abc" ; String result = "" ; Permutation p = new Permutation (); p.permutation(s,result,s.length()); } }
解法二 思想: July 方法
abc 为例子:
固定 a,求后面 bc 的全排列:abc,acb。求完后,a 和 b 交换;得到 bac,开始第二轮。
固定 b,求后面 ac 的全排列:bac,bca。求完后,b 和 c 交换;得到 cab,开始第三轮。
固定 c,求后面 ba 的全排列:cab,cba。
即递归树:
1 2 3 str: a b c ab ac ba bc ca cb result: abc acb bac bca cab cba
代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public class Permutation { public void permutation (String[] str , int first,int end) { if (first == end) { for (int j = 0 ; j <= end ;j++) { System.out.print(str[j]); } System.out.println(); } for (int i = first; i <= end ; i++) { swap(str, i, first); permutation(str, first+1 , end); swap(str, i, first); } } private void swap (String[] str, int i, int first) { String tmp; tmp = str[first]; str[first] = str[i]; str[i] = tmp; } public static void main (String args[]) throws Exception { String[] str = {"a" ,"b" ,"c" }; Permutation p = new Permutation (); p.permutation(str,0 ,2 ); } }
全组合 定义 输入三个字符 a、b、c,则它们的组合有 a、b、c、ab、ac、bc、abc。
解法 以位图的思想求解:假设原有元素 n 个,最终的组合结果有 $2^{n}-1$ 。 可以使用 $2^{n}-1$ 个位,1 表示取该元素,0 表示不取。所以 a 表示 001, ab 表示 011 ,以此类推。
代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class Combination { public void Combination (String [] s) { if (s.length == 0 ){ return ; } int len = s.length; int n = 1 <<len; for (int i=0 ;i<n;i++){ StringBuffer sb = new StringBuffer (); for (int j=0 ;j<len;j++){ if ( (i & (1 <<j)) != 0 ) { sb.append(s[j]); } } System.out.print(sb + " " ); } } public static void main (String[] args) { Combination c = new Combination (); String [] s = {"a" ,"b" ,"c" }; c.Combination(s); } }
斐波那契数列 定义 斐波那契数列( Fibonacci sequence ),又称黄金分割数列,指的是这样一个数列:1、1、2、3、5、8、13、21、34 …… 在数学上,斐波纳契数列以如下被以递归的方法定义:$F\left( 0\right) =0,F\left( 1\right) =1,F\left( n\right) = F\left( n-1\right) +F\left( n-2\right) \left( n\geq 2,n\in N^{\ast }\right)$
代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class Fibonacci { public int Fibo (int n) { if (n == 0 ){ return 0 ; } else if (n == 1 || n == 2 ){ return 1 ; } else { return Fibo(n-1 ) + Fibo(n-2 ); } } public static void main (String[] args) { Fibonacci f = new Fibonacci (); System.out.println(f.Fibo(3 )); } }
回文判断 定义 回文,是指正读和反读都一样的字符串,如 madam、level 等。时间复杂度 $O\left( n\right)$
代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public class Palindrome { public boolean isPalindrome (String s) { char [] array = s.toCharArray(); int head = 0 ; int end = s.length()-1 ; if (s.length() < 1 ){ return false ; } while (head < end){ if (array[head++] != array[end--]){ return false ; } } return true ; } public static void main (String[] args) { Palindrome p = new Palindrome (); System.out.println(p.isPalindrome("level" )); } }
归并排序 - Merge Sort 定义 归并排序是一个分治算法( Divide and Conquer )的一个典型实例,把一个数组分为两个大小相近(最多差一个)的子数组,分别把子数组都排好序之后通过归并( Merge )手法合成一个大的排好序的数组。
代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 import java.util.Arrays;public class MergeSort { public void sortArray (int [] array, int start, int end) { if (start == end){ return ; } int sort_size = end - start +1 ; int separate; if (sort_size % 2 == 0 ){ separate = start + sort_size/2 - 1 ; } else { separate = start +sort_size/2 ; } sortArray(array,start,separate); sortArray(array,separate +1 ,end); mergeArray(array,start,separate,end); } public void mergeArray (int [] array, int start, int separate, int end) { int total_size = end - start +1 ; int size1 = separate - start +1 ; int size2 = end -separate; int [] array1 = new int [size1]; int [] array2 = new int [size2]; for (int i = 0 ; i< size1; i++){ array1[i] = array[start + i]; } for (int i = 0 ; i<size2; i++){ array2[i] = array[separate + 1 + i]; } int merge_count = 0 ; int index1 = 0 ; int index2 = 0 ; while (merge_count < total_size){ if (index1 == size1){ for (int i = index2; i< size2; i++){ array[start + merge_count] = array2[i]; merge_count++; index2++; } } else if (index2 == size2){ for (int i = index1; i < size1; i++){ array[start + merge_count] = array1[i]; merge_count++; index1++; } } else { int value1 = array1[index1]; int value2 = array2[index2]; if (value1 == value2){ array[start + merge_count] = value1; array[start + merge_count +1 ] = value2; merge_count += 2 ; index1++; index2++; } else if (value1 < value2){ array[start + merge_count] = value1; merge_count++; index1++; } else { array[start + merge_count] = value2; merge_count++; index2++; } } } } public static void main (String[] args) { int array[] = { 10 ,9 ,8 ,7 ,6 ,5 ,4 ,3 ,2 ,1 ,0 ,-1 }; System.out.println("Original array: " +Arrays.toString(array)); MergeSort ms = new MergeSort (); ms.sortArray(array,0 ,array.length-1 ); System.out.println("Merge sorted array: " +Arrays.toString(array)); } }
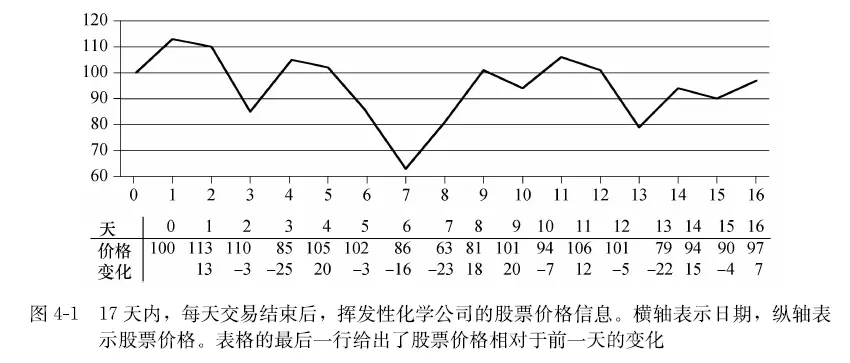
分治算法 - 求买卖股票的最大利润 定义 买卖一只股票,只允许交易一次,且买进的时间必须在卖出前,求最大利润。例: 数组 [10, 11, 7, 10, 6] 为某只股票价格的变化,则最大利润为 3,即价格为 7 时买进,价格为 10 时卖出。
详解
题目要求的是一次购买,一次卖出使得所获价格变化最大。可以考虑每一天的价格变化,第i天的价格变化 等于第i天的价格减去i-1天的价格,这样就会有许多价格变化的数据形成的数组,求这个数组的连续子数组的和的最大值就是答案了。为什么这个这个最大连续子数组就是答案?
假设原始数组是: a1 , a2 , a3 , a4 , a5 , … , an-1 , an , 若最大收益是 an - a1 2 - a1 , a3 - a2 , a4 - a3 , … , an-1 - an-2 , an - an-1 , 显然这个的连续和也是 an - an-1
问题转化为求最大连续子数组
假定我们要寻找子数组 A[low,...,high] 的最大子数组。使用分治法意味着我们要将子数组分成两个规模尽量相同的子数组。也就是说,找到子数组的中央位置,比如:mid ,然后考虑求两个子数组 A[low,...,mid] 和 A[mid+1,...,high] 。A[low,...,high] 的然后连续子数组 A[i,...,j] 所处的位置必然是一下三种情况之一:A[low,...,mid] 中,因此 low<=i<=j<=midA[mid+1,...,high]中,因此 mid+1<=i<=j<=highlow<=i<=mid<=j<=high
对于跨越中间点的最大子数组,可以在线性时间内求解。可以找出 A[i,...,mid] 和 A[mid+1,...,j] 的最大子数组,合并就是答案。
代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 public class MaxProfit { public int maxProfit (int [] prices) { if (prices == null || prices.length == 0 ){ return 0 ; } int [] differ_prices = new int [prices.length - 1 ]; for (int i = 1 ; i < prices.length; i++){ differ_prices[i-1 ] = prices[i] - prices[i-1 ]; } return findMaxSubArray(differ_prices,0 ,differ_prices.length - 1 ); } public int findMaxSubArray (int [] array, int start, int end) { if (start == end){ return Math.max(array[start], 0 ); } else { int mid = start + (end - start)/ 2 ; int left_sum = findMaxSubArray( array, start, mid); int right_sum = findMaxSubArray( array, mid+1 , end); int mid_sum = findMaxCrossingSubArray( array, start, mid, end); int sum = Math.max(left_sum, right_sum); sum = Math.max(sum, mid_sum); sum = Math.max(sum, 0 ); return sum; } } public int findMaxCrossingSubArray (int [] array, int start, int mid, int end) { if (start > mid || mid > end){ return Integer.MIN_VALUE; } int left_sum = Integer.MIN_VALUE; int right_sum = Integer.MIN_VALUE; int sum = 0 ; for (int i = mid; i >= start; i--){ sum += array[i]; if ( sum >= left_sum){ left_sum = sum; } } sum = 0 ; for (int j = mid+1 ; j <= end; j++){ sum += array[j]; if (sum>=right_sum){ right_sum = sum; } } return left_sum + right_sum; } public static void main (String[] args) { MaxProfit mp = new MaxProfit (); int [] array = {10 , 11 , 7 , 10 , 6 }; System.out.println("Max Profit: " + mp.maxProfit(array)); } }
逆序数求解 定义 对于 n 个不同的元素,先规定各元素之间有一个标准次序( 例如 n 个 不同的自然数,可规定从小到大为标准次序 ),于是在这 n 个元素的任一排列中,当某两个元素的先后次序与标准次序不同时,就说有 1 个逆序。一个排列中所有逆序总数叫做这个排列的逆序数。
例:有两个子序列 1467 和 2358i = 0, j = 0,即 1 和 2 。 1 < 2,所以关于 1 的逆序数为 j = 0。接下来 i++, i = 1 指向 4 ,4 > 2,j 向右移动,j 最终指向 5,j = 2,所以关于 5 的逆序数为 2( 5 前面的 2、3 均小于 4 )。 同理关于 6、7 的逆序数均为 3。所以 整个序列的逆序数 = 2 + 3 + 3 + 两子序列未有序前的逆序数。
代码 Java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 public class InverseNumber { public int countInversions (int [] array, int start, int end) { if (start == end){ return 0 ; } int size = end - start +1 ; int middle; if (size % 2 == 0 ){ middle = start + size/2 -1 ; } else { middle = start + size/2 ; } int left_count = countInversions(array, start, middle); int right_count = countInversions(array, middle+1 , end); int merge_count = mergeArray(array, start, middle, end); return left_count + right_count + merge_count; } public int mergeArray (int [] array, int start, int middle, int end) { int total_size = end -start +1 ; int left_size = middle - start +1 ; int right_size = end - middle; int [] left_array = new int [left_size]; int [] right_array = new int [right_size]; for (int i = 0 ; i < left_size; i++){ left_array[i] = array[start + i]; } for (int i = 0 ; i< right_size; i++){ right_array[i] = array[middle + 1 + i]; } int merge_size = 0 ; int left_head = 0 ; int right_head = 0 ; int count = 0 ; while (merge_size < total_size){ if (left_head == left_size){ for (int i = right_head; i<right_size; i++){ array[start + merge_size] = right_array[i]; merge_size++; right_head++; } } else if (right_head == right_size){ for (int i = left_head; i<left_size; i++){ array[start + merge_size] = left_array[i]; merge_size++; left_head++; count += right_head; } } else { int left_value = left_array[left_head]; int right_value = right_array[right_head]; if (left_value < right_value){ array[start + merge_size] = left_value; merge_size++; left_head++; count += right_head; } else { array[start + merge_size] = right_value; merge_size++; right_head++; } } } return count; } public static void main (String[] args) { InverseNumber in = new InverseNumber (); int [] array = {1 , 4 , 6 , 7 , 2 , 3 , 5 , 8 }; System.out.println("Inversion count: " + in.countInversions(array,0 ,array.length-1 )); } }
C++ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 #include <iostream> #include <random> #include <vector> #include <ctime> using std::cin;using std::cout;using std::endl;static int count = 0 ;int InverseNumber_BubbleSort (const std::vector<int > & vector) for (auto iter = vector.cbegin (); iter != vector.cend (); ++iter) { for (auto iter2 = iter + 1 ; iter2 != vector.cend (); ++iter2) { if (*iter > *iter2) { ++count; } } } return count; } void printArray (std::vector<int > vector) std::vector<int > ms_SortArray (std::vector<int > vector) ;std::vector<int > ms_MergeArray (std::vector<int > front, std::vector<int > end) ;int InverseNumber_MergeSort (const std::vector<int > & vector) std::vector<int > vec{vector.cbegin (), vector.cend ()}; ms_SortArray (vec); return count; } std::vector<int > ms_SortArray (std::vector<int > vector) std::vector<int > vec_front; std::vector<int > vec_end; if (vector.size () == 1 ) { return vector; } if (vector.size () & 1 ) { vec_front.assign (vector.cbegin (), vector.cbegin () + vector.size () / 2 + 1 ); vec_end.assign (vector.cbegin () + vector.size () / 2 + 1 , vector.cend ()); vec_front = ms_SortArray (vec_front); vec_end = ms_SortArray (vec_end); } else { vec_front.assign (vector.cbegin (), vector.cbegin () + vector.size () / 2 ); vec_end.assign (vector.cbegin () + vector.size () / 2 , vector.cend ()); vec_front = ms_SortArray (vec_front); vec_end = ms_SortArray (vec_end); } return ms_MergeArray (vec_front, vec_end); } std::vector<int > ms_MergeArray (const std::vector<int > front, const std::vector<int > end) std::vector<int > v; size_t total_size = front.size () + end.size (); size_t front_size = front.size (); size_t end_size = end.size (); size_t merge_count = 0 ; size_t index1 = 0 ; size_t index2 = 0 ; while (merge_count < total_size) { if (index1 == front_size) { for (size_t i = index2; i < end_size; ++i) { v.push_back (end.at (i)); ++merge_count; ++index2; } } else if (index2 == end_size) { for (size_t i = index1; i < front_size; ++i) { v.push_back (front.at (i)); ++merge_count; ++index1; } } else { int value1 = front.at (index1); int value2 = end.at (index2); if (value1 == value2) { v.push_back (value1); ++merge_count; ++index1; } else if (value1 < value2) { v.push_back (value1); ++merge_count; ++index1; } else { v.push_back (value2); ++merge_count; ++index2; count += front_size - index1; } } } return v; } std::vector<int > vecGen (size_t length) std::vector<int > vec (length) ; std::random_device random_device; static std::default_random_engine engine (random_device()) static std::uniform_int_distribution<int > u (1 , 9 ) for (int i = 0 ; i < length; ++i) { vec[i] = u (engine); } return vec; } void printArray (std::vector<int > vector) for (const int i : vector) { cout << i << " " ; } cout << endl; } int main () size_t len; clock_t tbegin, tend; cout.setf (std::ios::fixed, std::ios::floatfield); cout << "求逆序数:" << endl; cout << "请输入数组长度:" << endl; cin >> len; std::vector<int > vector = vecGen (len); printArray (vector); cout << "求逆序数后:" << endl; cout << endl; tbegin = clock (); cout << "逆序数为:" << InverseNumber_BubbleSort (vector) << endl; tend = clock (); cout << "花费时间为:" << double (tend - tbegin) / CLOCKS_PER_SEC * 1000 << " ms" << endl; cout << endl; count = 0 ; tbegin = clock (); cout << "逆序数为:" << InverseNumber_MergeSort (vector) << endl; tend = clock (); cout << "花费时间为:" << double (tend - tbegin) / CLOCKS_PER_SEC * 1000 << " ms" << endl; return 0 ; }
贪心算法 - Greedy Algorithm 思想 贪心算法是一种在每一步选择中都采取在当前状态下最好或最优(即最有利)的选择,从而希望导致结果是最好或最优的算法
贪心算法并不是从整体最优考虑,它所做出的选择只是在某种意义上的局部最优。贪心算法对于大部分的优化问题都能产生最优解,但不能总获得整体最优解,通常可以获得近似最优解。
零钱问题 描述 假如某种货币有如下几种面值:1 元,5 元,10 元,25 元,100 元。如果给定需为某客户找零的数额,那么如何组合该货币的几种面值,从而使得客户所得的找零的张数最少。
代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 import java.util.ArrayList;import java.util.Arrays;public class GetMinCoins { public ArrayList GetCoins (int [] coins, int coin_amount) { ArrayList<Integer> coin_list = new ArrayList <>(); Arrays.sort(coins); for (int i = coins.length - 1 ; i >= 0 ; i--){ int coin_count = coin_amount / coins[i]; for (int j = 0 ; j<coin_count; j++){ coin_list.add(coins[i]); } coin_amount -= coin_count * coins[i]; } return coin_list; } public static void main (String[] args) { int [] coins = {1 , 5 , 10 , 25 , 100 }; int coin_amount = 34 ; System.out.println("Coin amount: " + coin_amount); GetMinCoins gm = new GetMinCoins (); System.out.println("Coins list: " +gm.GetCoins(coins,coin_amount)); } }
多背包问题 问题 有多个背包,每个背包容量不同;有若干物品,每个物品都有各自的价值和体积,每个物品有且只有一个,即一个物品要么装不进背包,要么只能装在一个背包中;现要求在背包中装入尽可能多的物品,求能装下的最大价值。
解法一:贪心算法 思想 利用贪心算法,先求出每个物品的性价比,即 value / weight ;然后将物品按性价比从大到小排序;将背包按容量从小到大排序;尝试将物品优先放入容量小的背包中。
有三种思路,将背包按容量从小到大排序,从容量小的背包开始放;按容量
代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 import java.util.ArrayList;import java.util.Collections;import java.util.Comparator;public class GreedyAlgorithm { public static class ItemComparator implements Comparator <Item>{ @Override public int compare (Item item1, Item item2) { if (item1.getPriceRatio() > item2.getPriceRatio()){ return -1 ; } else if (item1.getPriceRatio() < item2.getPriceRatio()){ return 1 ; } else { return 0 ; } } } public static class KnapsackComparator implements Comparator <Knapsack>{ @Override public int compare (Knapsack knapsack1, Knapsack knapsack2) { return Integer.compare(knapsack1.getCapacity(), knapsack2.getCapacity()); } } public static void main (String[] args) { Item item1 = new Item ("1" , 40 , 10 ); Item item2 = new Item ("2" , 30 , 15 ); Item item3 = new Item ("3" , 15 , 5 ); Item item4 = new Item ("4" , 25 , 25 ); Knapsack pack1 = new Knapsack ("1" , 15 ); Knapsack pack2 = new Knapsack ("2" , 20 ); Knapsack pack3 = new Knapsack ("3" , 10 ); ArrayList<Item> item_array = new ArrayList <>(); item_array.add(item1); item_array.add(item2); item_array.add(item3); item_array.add(item4); Collections.sort(item_array, new ItemComparator ()); ArrayList<Knapsack> knapsacks_array = new ArrayList <>(); knapsacks_array.add(pack1); knapsacks_array.add(pack2); knapsacks_array.add(pack3); Collections.sort(knapsacks_array, new KnapsackComparator ()); for (int i = 0 ; i < knapsacks_array.size(); i++){ Knapsack temp_knapsack = knapsacks_array.get(i); int temp_capacity = temp_knapsack.getCapacity(); for (int j = 0 , item_size = item_array.size(); j < item_size; j++){ Item temp_item = item_array.get(j); if (temp_item.getWeight() <= temp_capacity){ temp_knapsack.addValue(temp_item.getValue()); temp_knapsack.addIDContain(temp_item.getId()); temp_capacity -= temp_item.getWeight(); item_array.remove(j); item_size--; j--; } } temp_knapsack.printTotalValue(); } } } class Item { private String id; private int value; private int weight; private double price_ratio; public Item (String id, int value, int weight) { this .id = id; this .value = value; this .weight = weight; this .price_ratio = (double ) value / weight; } public double getPriceRatio () { return this .price_ratio; } public int getWeight () { return this .weight; } public int getValue () { return this .value; } public String getId () { return this .id; } } class Knapsack { private String id; private String id_contain; private int capacity; private int total_value; public Knapsack (String id, int capacity) { this .id = id; this .capacity = capacity; this .total_value = 0 ; this .id_contain = "" ; } public int getCapacity () { return this .capacity; } public void addValue (int value) { this .total_value += value; } public void addIDContain (String id) { this .id_contain += id; } public void printTotalValue () { System.out.println("Knapsack ID: " + this .id + " Total Value: " + this .total_value + " Item ID contain: " + this .id_contain ); } }
解法二:Improving Search (Neighborhood Search) Algorithm - 邻接算法 思想
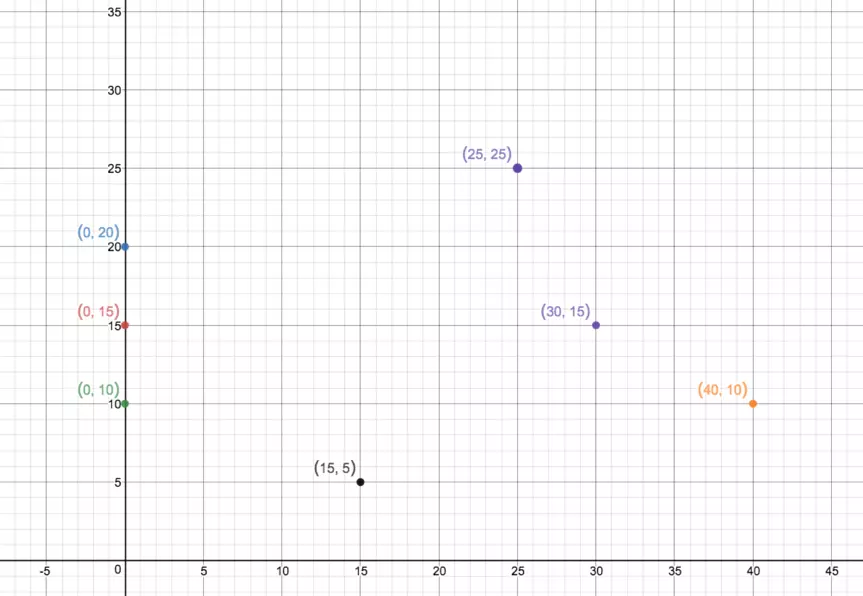
如图,建立指教坐标系。X 轴代表价值,Y 轴代表体积(容量)。所有背包按容量从小到大分布在 Y 轴上,物品分布在第一象限上。从最小容量的背包开始,寻找体积小于等于该背包容量的物品,计算每个物品与背包之间的距离,并寻找距离最大值。再以找到的点为基准,继续寻找体积小于等于装入一个物品后的背包容量且距离最远的点(物品),一次类推,直到没有符合条件的物品为止。将装入背包的点(物品)排除,从容量倒数第二小的背包开始继续进行以上操作,直至全部完成。
以图为例:绿点(0,10)为容量最小的背包,小于等于该背包容量的物品为黄点(40,10)和黑点(15,5),寻找距离最长的点,即黄点。黄点装入绿点背包,排除,再以黄点为基础寻找容量小于等于装入黄点后的绿点背包,且距离最远的物品。因为绿点背包容量已满,所以将红点(0,15)背包作为起始点,以此类推。
始终选择距离最远点的原因:尽可能将重量大价值小(即性价比低)的物品装入小容量背包中,避免某一个可能存在的大容量背包一直装入低性价比物品,从而导致空间浪费。
代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 import java.util.*;public class NeighborhoodSearch { public static void findOptimalSolution (ArrayList<Knapsack> knapsack_array, ArrayList<Item> item_array) { ArrayList<Item> temp_item_array = item_array; for (int i = 0 ; i < knapsack_array.size(); i++){ Knapsack temp_knapsack = knapsack_array.get(i); int temp_capacity = temp_knapsack.getCapacity(); HashMap<Item, Double> hashmap = new HashMap <>(); ArrayList<Item> temp_array = new ArrayList <>(); for (int j = 0 ; j < temp_item_array.size(); j++){ Item temp_item = temp_item_array.get(j); if (temp_item.getWeight() <= temp_capacity ){ temp_array.add(temp_item); double distance = getDistance( temp_knapsack.getValue(), temp_knapsack.getCapacity(), temp_item.getValue(), temp_item.getWeight() ); hashmap.put(temp_item, distance); } } List<Map.Entry<Item,Double>> list = hashMapCompare(hashmap); Item head = null ; if (list != null ){ head = list.get(0 ).getKey(); temp_item_array.remove(head); temp_array.remove(head); temp_knapsack.addIDContain(head.getId()); temp_knapsack.addValue(head.getValue()); temp_capacity = temp_knapsack.getCapacity() - head.getWeight(); } while (hashmap != null ) { hashmap.clear(); hashmap = null ; for (int j = 0 ; j < temp_array.size(); j++) { Item temp_item = temp_array.get(j); if (temp_item.getWeight() <= temp_capacity) { double distance = getDistance(head.getValue(), head.getWeight(), temp_item.getValue(), temp_item.getWeight()); hashmap.put(temp_item, distance); } } list = hashMapCompare(hashmap); if (list != null ) { head = list.get(0 ).getKey(); temp_item_array.remove(head); temp_array.remove(head); temp_knapsack.addIDContain(head.getId()); temp_knapsack.addValue(head.getValue()); temp_capacity = temp_knapsack.getCapacity() - head.getWeight(); } } temp_knapsack.printTotalValue(); } } public static List<Map.Entry<Item,Double>> hashMapCompare(Map<Item, Double> map){ if (map == null ) return null ; List<Map.Entry<Item, Double>> list = new ArrayList <>(map.entrySet()); Collections.sort(list, new Comparator <Map.Entry<Item, Double>>() { @Override public int compare (Map.Entry<Item, Double> o1, Map.Entry<Item, Double> o2) { return -o1.getValue().compareTo(o2.getValue()); } }); return list; } public static double getDistance (int x1, int y1, int x2, int y2) { double d = (x1 - x2) * (x1 - x2) + (y1 - y2) * (y1 - y2); return Math.sqrt(d); } public static class KnapsackComparator implements Comparator <Knapsack>{ @Override public int compare (Knapsack knapsack1, Knapsack knapsack2) { return Integer.compare(knapsack1.getCapacity(), knapsack2.getCapacity()); } } public static void main (String[] args) { Item item1 = new Item ("1" , 40 , 10 ); Item item2 = new Item ("2" , 30 , 15 ); Item item3 = new Item ("3" , 15 , 5 ); Item item4 = new Item ("4" , 25 , 25 ); Knapsack pack1 = new Knapsack ("1" , 15 ); Knapsack pack2 = new Knapsack ("2" , 20 ); Knapsack pack3 = new Knapsack ("3" , 10 ); ArrayList<Knapsack> knapsack_array = new ArrayList <>(); knapsack_array.add(pack1); knapsack_array.add(pack2); knapsack_array.add(pack3); Collections.sort(knapsack_array, new KnapsackComparator ()); ArrayList<Item> item_array = new ArrayList <>(); item_array.add(item1); item_array.add(item2); item_array.add(item3); item_array.add(item4); findOptimalSolution(knapsack_array, item_array); } } class Item { private String id; private int value; private int weight; public Item (String id, int value, int weight) { this .id = id; this .value = value; this .weight = weight; } public int getWeight () { return this .weight; } public int getValue () { return this .value; } public String getId () { return this .id; } } class Knapsack { private String id; private String id_contain; private int capacity; private int total_value; public Knapsack (String id, int capacity) { this .id = id; this .capacity = capacity; this .total_value = 0 ; this .id_contain = "" ; } public int getCapacity () { return this .capacity; } public int getValue () { return this .total_value; } public void addValue (int value) { this .total_value += value; } public void addIDContain (String id) { this .id_contain += id; } public void printTotalValue () { System.out.println("Knapsack ID: " + this .id + " Total Value: " + this .total_value + " Item ID contain: " + this .id_contain ); } }
动态规划 最长递增子序列 - LIS 思想 最长递增子序列(longest increasing subsequence)问题是指,在一个给定的数值序列中,找到一个子序列,使得这个子序列元素的数值依次递增,并且这个子序列的长度尽可能地大。最长递增子序列中的元素在原序列中不一定是连续的。
例:
0, 8, 4, 12, 2, 10, 6, 14, 1, 9, 5, 13, 3, 11, 7, 15
最长递增子序列为
0, 2, 6, 9, 11, 15
值得注意的是原始序列的最长递增子序列并不一定唯一,对于该原始序列,实际上还有以下两个最长递增子序列
0, 4, 6, 9, 11, 15 和 0, 4, 6, 9, 13, 15
定义 dp[i] 为以 ai 为末尾的最长递增子序列的长度,故以 ai 结尾的递增子序列
要么是只包含 ai 的子序列
要么是在满足 j < i 并且 aj < ai 的以 ai 为结尾的递增子序列末尾,追加上 ai 后得到的子序列
如此,便可建立递推关系,在 $O\left( n^{2}\right)$ 时间内解决这个问题。
代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 public class LIS { public static int findLIS (int [] array) { int [] dp = new int [array.length]; for (int i = 0 ; i < dp.length; i++){ dp[i] = 1 ; } int max = 1 ; for (int i = 1 ; i < array.length; i++){ for (int j = 0 ; j < i; j++){ if (array[j] < array[i] && dp[j] + 1 > dp[i]){ dp[i] = dp[j] + 1 ; } if (max < dp[i]){ max = dp[i]; } } } printSubsequence(dp, array); return max; } private static void printSubsequence (int [] dp, int [] array) { int j = 1 ; for (int i = 0 ; i < dp.length; i++){ if (dp[i] == j){ System.out.print(array[i] + " " ); j++; } } } public static void main (String[] args) { int max; int [] array = {18 , 17 , 19 , 6 , 11 , 21 , 23 , 15 }; System.out.println("One of the longest increasing subsequence: " ); max = findLIS(array); System.out.println(); System.out.println("Size: " + max); } }
求连续的扑克牌 问题 有 n 张扑克,有四种花色,扑克面值为 0 ~ 9、J、Q、K、A,花色相同或者面值相同的两张扑克可以进行连接。其中,面值为 8 的扑克可以与任意的扑克进行连接,从这 n 张牌中找出最长的连接组合。
代码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 import java.util.ArrayList;public class LCP_DP { public static int findLCP (ArrayList<Poker> arraylist) { int [] dp = new int [arraylist.size()]; for (int i = 0 ; i < dp.length; i++){ dp[i] = 1 ; } int max = 1 ; for (int i = 1 ; i < arraylist.size(); i++){ for (int j = 0 ; j < i; j++){ if (arraylist.get(j).getNum().equals(arraylist.get(i).getNum()) || arraylist.get(j).getSuit().equals(arraylist.get(i).getSuit()) || arraylist.get(j).getNum().equals(Integer.toString(8 )) || arraylist.get(i).getNum().equals(Integer.toString(8 )) && dp[j] + 1 > dp[i] ){ dp[i] = dp[j] + 1 ; } if (max < dp[i]){ max = dp[i]; } } } printPoker(dp, arraylist, max); return max; } private static void printPoker (int [] dp, ArrayList<Poker> arraylist, int max) { int j = max; for (int i = dp.length -1 ; i >= 0 ; i--){ if (dp[i] == j){ System.out.println("Suit: " + arraylist.get(i).getSuit() + " Num: " + arraylist.get(i).getNum()); j--; } } } public static void main (String[] args) { int max; ArrayList<Poker> arraylist = new ArrayList <>(); Poker p1 = new Poker ("spade" , "7" ); Poker p2 = new Poker ("heart" , "7" ); Poker p3 = new Poker ("spade" , "k" ); Poker p4 = new Poker ("club" , "k" ); Poker p5 = new Poker ("heart" , "8" ); arraylist.add(p1); arraylist.add(p2); arraylist.add(p3); arraylist.add(p4); arraylist.add(p5); System.out.println("The index of Poker: " ); max = findLCP(arraylist); System.out.println(); System.out.println("Size: " + max); } } class Poker { private String suit; private String num; Poker(String suit, String num){ this .suit = suit; this .num = num; } public String getSuit () { return this .suit; } public String getNum () { return this .num; } }
参考