from langchain_core.prompts import PromptTemplate from langchain_core.output_parsers import StrOutputParser
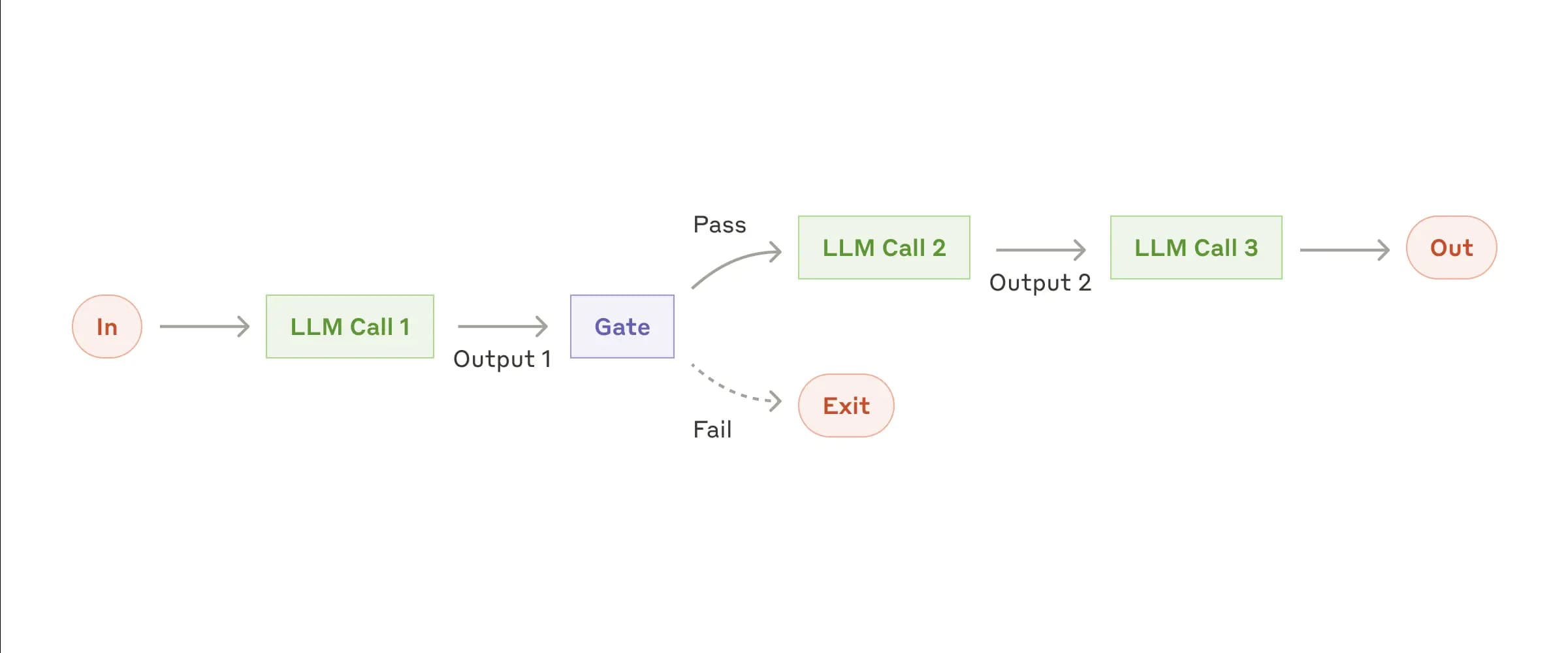
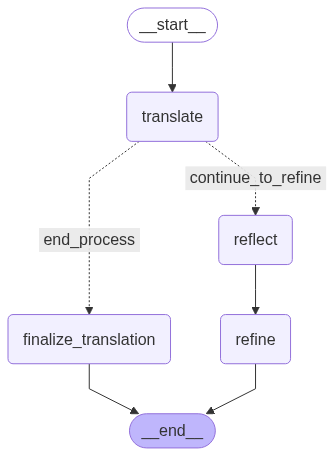
translate_prompt = PromptTemplate( template="""You are an expert translator. Translate the following text from {source_language} to {target_language}. Provide only the translated text, without any additional explanations or preambles. Original Text: {text} """, input_variables=["source_language", "target_language", "text"], )
translator_chain = translate_prompt | model | StrOutputParser()
quality_check_prompt = PromptTemplate( template="""You are a strict translation quality reviewer. Review the initial translation based on the original text. Does the translation accurately convey the meaning, style, and nuances of the original? Answer with a single word: "Good" if the translation is excellent and needs no changes, or "Bad" if it has any issues or could be improved. Original Text ({source_language}): {original_text} Initial Translation ({target_language}): {initial_translation} Your single-word assessment: """, input_variables=["original_text", "initial_translation", "source_language", "target_language"], )
quality_check_chain = quality_check_prompt | model | StrOutputParser()
reflect_prompt = PromptTemplate( template="""You are a senior translation reviewer. Your task is to review a translation based on the original text. Identify any potential issues in the translation regarding fluency, accuracy, terminology, and cultural nuances. Provide a concise list of constructive feedback and suggestions for improvement. Original Text ({source_language}): {original_text} Initial Translation ({target_language}): {initial_translation} Your Reflection and Suggestions: """, input_variables=["original_text", "initial_translation", "source_language", "target_language"], )
reflection_chain = reflect_prompt | model | StrOutputParser()
refine_prompt = PromptTemplate( template="""You are a master translator responsible for producing the final version of a translation. Use the original text, the initial translation, and the reviewer's reflection to create a polished and high-quality final translation. Integrate the suggestions from the reflection to improve upon the initial version. Provide only the final, refined translated text. Original Text ({source_language}): {original_text} Initial Translation ({target_language}): {initial_translation} Reviewer's Reflection and Suggestions: {reflection} Final Polished Translation: """, input_variables=["original_text", "initial_translation", "reflection", "source_language", "target_language"], )
refine_chain = refine_prompt | model | StrOutputParser()