Bitcask 存储引擎:一个用于快速键/值数据的日志结构哈希表
需求
在 Bitcask 诞生之前,并没有一个能够满足如下全部需求的存储引擎:
- 读/写的低延时
- 随机写场景下的高吞吐
- 支持数据量远大于内存的持久化存储
- 异常恢复机制,能够快速恢复且不丢数据
- 便捷得数据备份机制
- 支持易理解的数据结构
- 大并发/大数据量下的引擎稳定性保障
在这样的背景下,Riak 团队开发了 Bitcask。
磁盘数据结构
一个 Bitcask 实例是一个目录,并且强制在一个特定的时间内只有一个操作系统进程会打开这个实例进行写入。可以把这个进程看成是 “数据库服务器”。在任何时候,该目录中的一个文件是 “活动” 的,供服务器写入。当该文件达到一个大小阈值时,它将被关闭,并创建一个新的活动文件。一旦一个文件被关闭,无论是有目的的还是由于服务器退出,它都被认为是不可改变的,并且永远不会再被打开进行写入。
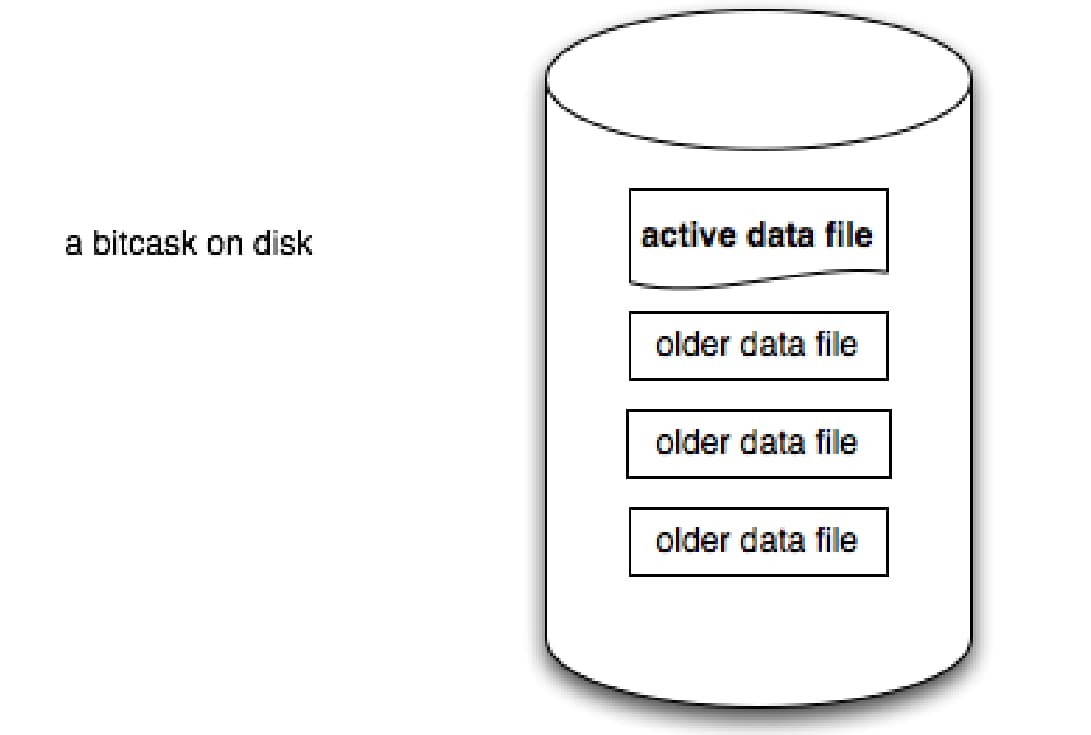
活动文件只通过追加写入,这意味着连续写入不需要磁盘寻址。为每个键/值条目(entry)写入的格式是简单的:
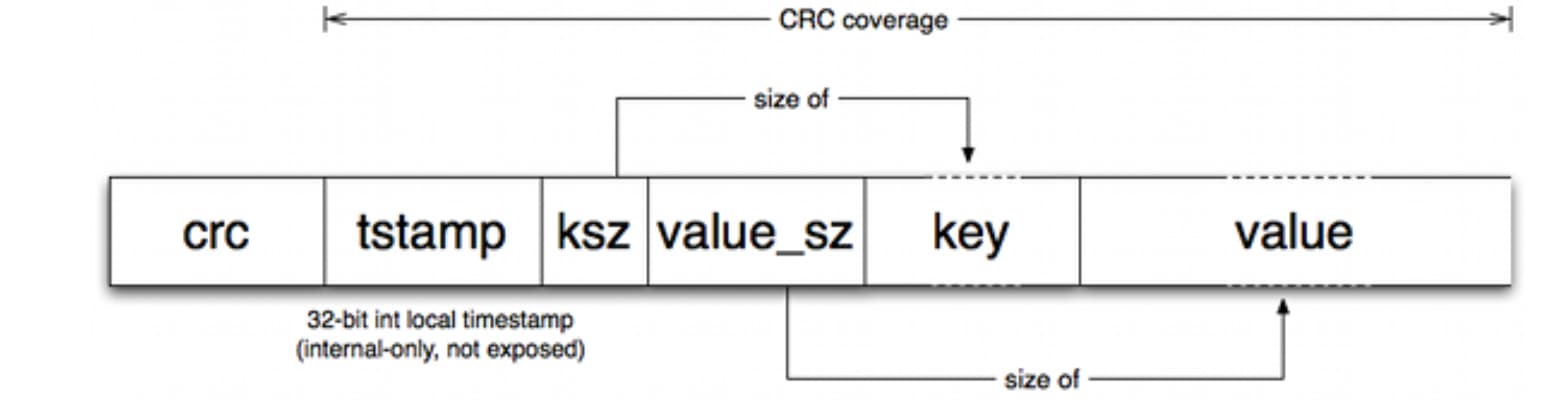
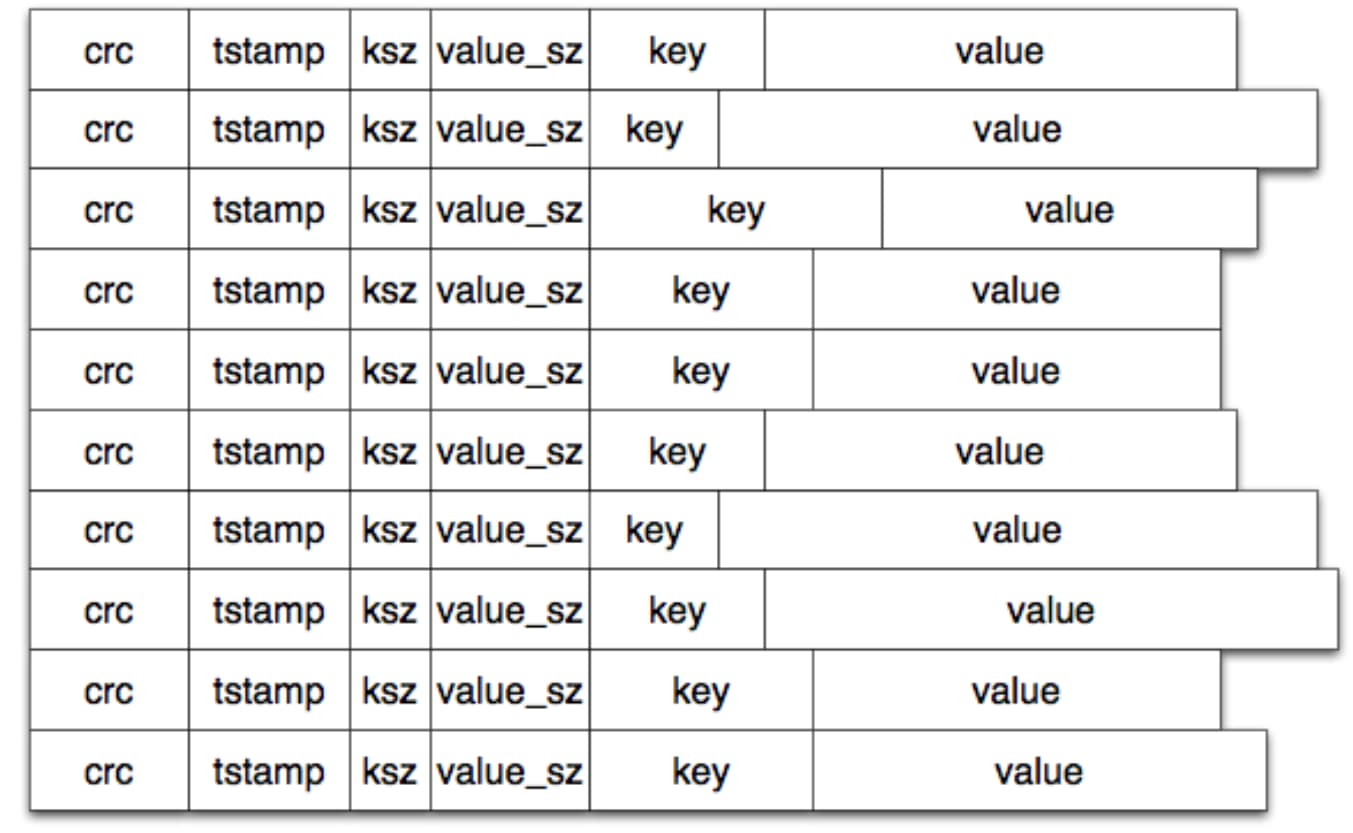
每写一次,就有一个新的条目被追加到活动文件中。请注意,删除只是写入一个特殊的墓碑值,它将在下一次合并中被删除。因此,一个 Bitcask 数据文件只不过是这些条目的一个线性序列:
内存数据结构
附加完成后,一个叫做 keydir 的内存数据结构被更新。keydir 是一个简单的哈希表,它将 Bitcask 中的每个键映射到一个固定大小的结构中,给出该键最近写入的文件、偏移和大小。

当写入发生时,keydir 被原子化地更新为最新的数据的位置。旧的数据仍然存在于磁盘上,但任何新的读取将使用 keydir 中的最新版本。正如稍后所见,合并过程将最终删除旧值。
读取流程
读取一个值很简单,而且不需要超过一次磁盘搜索。在 keydir 中查找键,然后从那里使用查找返回的文件 ID、位置和大小来读取数据。在许多情况下,操作系统的文件系统预读缓存使这个操作比预期的要快得多。
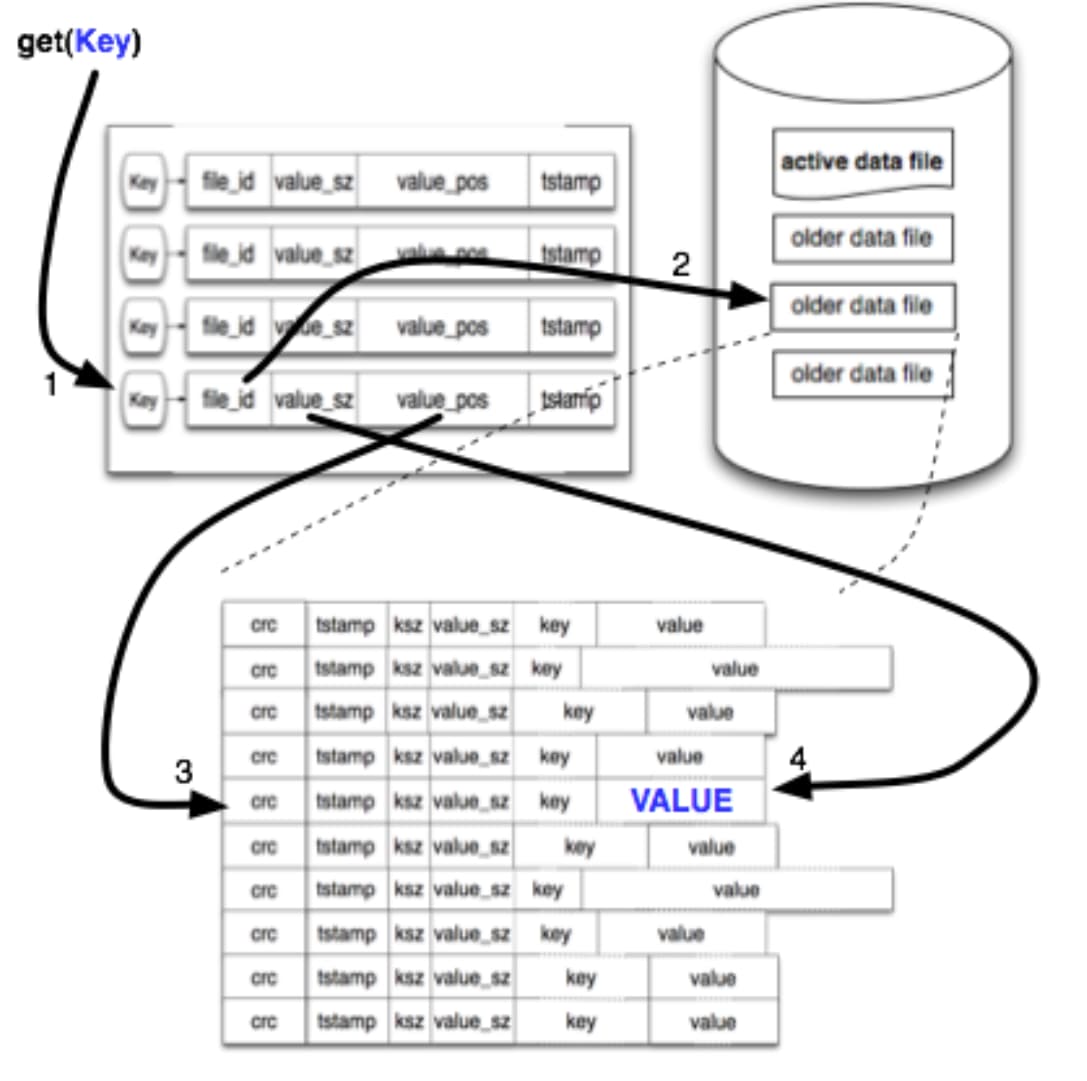
根据上图整理出步骤如下:
- 从内存的哈希表中找到之前写入的
key,取出这个key数据所在的file_id - 根据
file_id找到对应的data file - 根据
value_pos找到data file上的指定entry - 从
entry的末尾向前读取value_sz的数据,即为key的value数据
数据合并
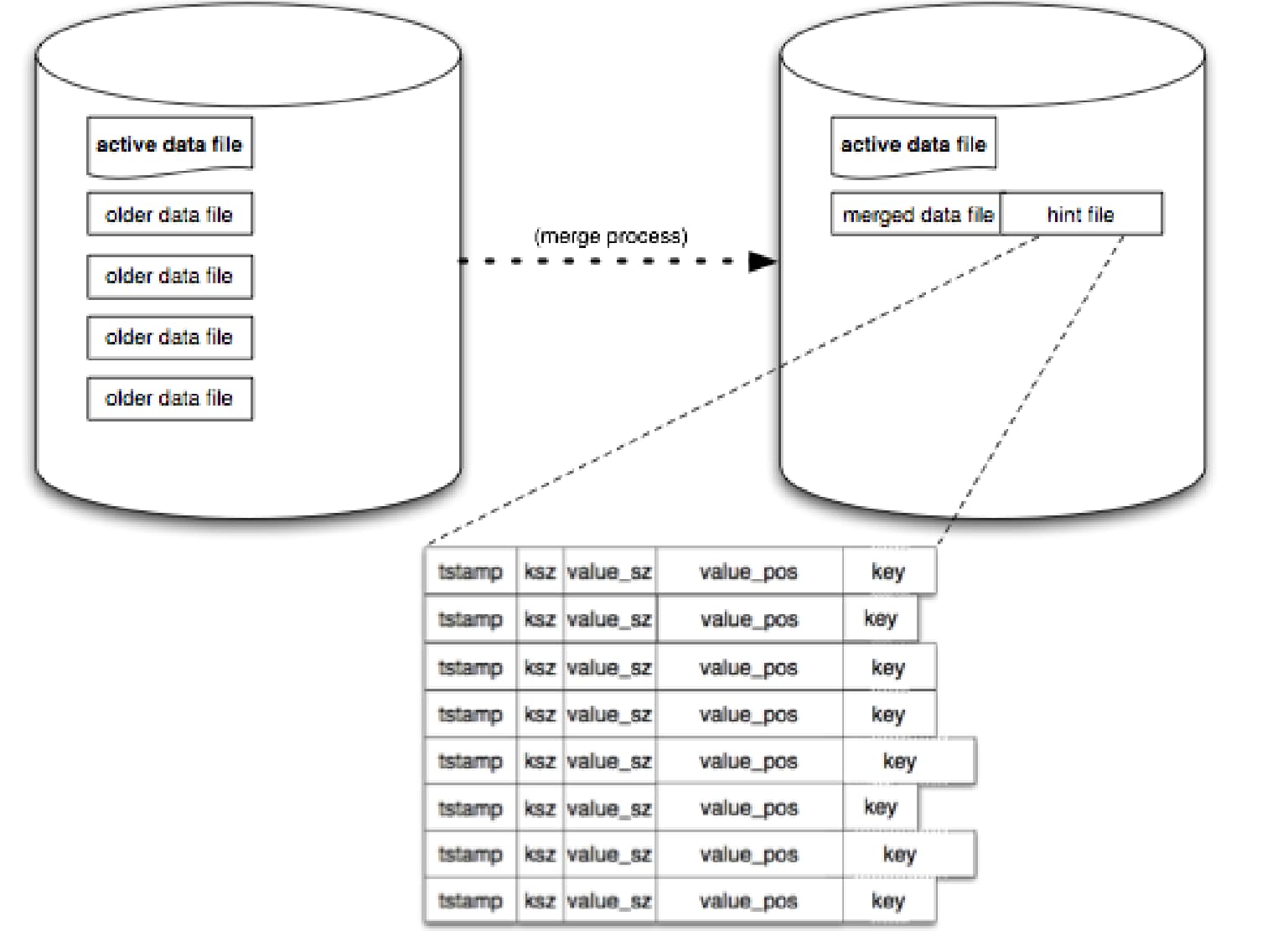
这个简单的模型可能会随着时间的推移而占用大量的空间,因为只是写出了新的数值而没有触及旧的数值。一个被称为 “合并” 的压缩过程解决了这个问题。合并过程遍历 Bitcask 中所有非活动(即不可变)的文件,并产生一组数据文件作为输出,其中只包含每个当前键的 “实时” 或最新版本。
完成这些工作后,会在每个数据文件旁边创建一个 “提示文件”。这些文件本质上与数据文件一样,但它们不包含数值,而是包含相应数据文件中数值的位置和大小。